
Why we need a standardized cybersecurity classification system
How we can borrow a system that has worked incredibly well in healthcare and adopt it in cybersecurity

Cybersecurity has a data problem. Decades later, we are still struggling to understand the efficacy of security controls, especially when looking at the aggregated, industry-wide level. Two of the widely followed reports, Verizon Data Breach Investigations Report and CrowdStrike Global Threat Report, despite their comprehensiveness, do not represent the whole industry globally or even in the US, and leave out a lot of important data. If we look at other, less credible sources, it becomes clear that we can't trust most stats about the cybersecurity industry, and we must stop creating numbers out of thin air.
Many would argue that security is too complex to be measured, so we should just accept our reliance on what Daniel Geer, Kevin Soo Hoo, and Andrew Jaquith described as “oracles and soothsayers”, and stop trying to get better data. In this piece, I am arguing that things aren’t that bad and that we can borrow best practices from other areas such as healthcare.
Thanks to Ed Covert for an inspiration to write this piece, deep discussions, and great perspectives on this topic.
Welcome to Venture in Security! Before we begin, do me a favor and make sure you hit the “Subscribe” button. Subscriptions let me know that you care and keep me motivated to write more. Thanks folks!
This issue is brought to you by… Vanta
7 steps to an airtight GRC strategy
The information security landscape is constantly changing, which is why it’s important to have a scalable and secure strategy that evolves alongside it.
Implementing a GRC program can provide your organization with a structured, proactive approach to managing its IT security that helps your business meet its goals.
Learn how to implement a GRC framework with Vanta’s tactical guide.
Here’s what’s inside:
Overview of GRC strategy
The three components that make up a GRC framework
The steps needed to implement GRC for your organization
Medical classification, its scope, and significance for healthcare
When we think about the need to codify cybersecurity, it’s tempting to argue that it’s not feasible because of how complex our industry has become and how interconnected everything is. Instead of diving into that debate, let’s start by taking a closer look at the practice of medical classification.
There are hundreds of thousands of various diseases, medical procedures, and healthcare services. In order to conduct statistical analysis of diseases and treatment, design decision support systems for doctors, identify and track epidemic outbreaks, and perform forensic analysis, all this unstructured data needs to be standardized. This is where medical classification, or medical coding, comes in.
Medical coding is the process of codifying the person’s health care information such as diagnosis, procedures, and necessary equipment, and translating it into universal alphanumeric codes. As Wikipedia explains, there are four types of codes:
Diagnostic codes are used to classify symptoms, diseases, illnesses, and causes of death.
Procedural codes are used to describe treatment (procedures) provided by medical professionals. For instance, the system used in the US called the ICD-10 Procedure Coding System (ICD-10-PCS), would define the Plain Radiography of a Single Coronary Artery using High Osmolar using the code B2000ZZ.
Pharmaceutical codes are used to identify medication. In the US, for example, the National Drug Code (NDC) is a unique product identifier used for drugs intended for human use. A bottle of Tylenol, for example, has the national drug code 50580-488-10.
Topographical codes are used to describe a specific location in the body.
These codes are critical for healthcare, public health planning, health insurance, and many other areas we take for granted. Without medical coding, it would not be possible to effectively process medical claims, identify early signs of epidemics, and statistically prove that a specific type of treatment is effective against a certain kind of disease.
This isn’t to say that there are no problems with the way medical classification works today. However, the World Health Organization (WHO) has been working tirelessly to facilitate the comparison of health-related data within and across populations and over time as well as the compilation of nationally consistent data.
A standardized cybersecurity classification system could change the state of the industry
The need for standardized classification in cybersecurity
In cybersecurity, we lack a standardized way to classify, analyze, and represent data. I have always believed that cyber insurance has the potential to play a pivotal role in accelerating the maturation of cybersecurity. Many in the industry know that we lack data. The argument I often hear is that while we have many decades of records about car accidents, diseases, and causes of death, the data we have about cyber at best covers a decade. While that may be true, the reality is that the threat landscape in security changes so rapidly that there would be little value in looking thirty years back. What we need isn’t more data, it’s a better way to classify the data we are able to gather today.
In order for us to develop a standardized cybersecurity classification system similar to medical classification, we need ways to codify:
Tactics and techniques adversaries use to achieve their goals (the cyber equivalent of the diagnostic codes).
Countermeasures defenders can employ to prevent malicious attacks (the cyber equivalent of the procedural codes).
Security capabilities offered by different tools (cyber equivalent of the pharmaceutical codes).
Ways to describe where the attacks are observed (the cyber equivalent of the topographical codes).
Adopting a standardized cybersecurity classification system inspired by medical coding could give us a common language to describe attacks, techniques, and preventative controls. This, in turn, would enable us to move closer towards evidence-based security. Without developing a common language, it’s hard for us to measure if the things we’re spending time and money on are indeed leading to risk quantifiable reduction.
The good news is that we are more than halfway there
The good news is that we are more than halfway there, to a large degree thanks to the work of MITRE, a not-for-profit corporation committed to the public interest, operating federally funded R&D centers on behalf of the government sponsors in the US.
The first step to developing a standardized classification system for security is to catalog tactics and techniques adversaries use to achieve their goals (the cyber equivalent of the diagnostic codes). MITRE has done a fantastic job here with its ATT&CK (Adversarial Tactics, Techniques, and Common Knowledge) framework which does exactly that - classifying and describing cyberattacks and intrusions. MITRE ATT&CK has gained widespread adoption in the security industry. A large number of security vendors, from Endpoint Detection and Response (EDR) to Security Event and Information Management (SIEM) and Threat Intelligence (TI) companies incorporated ATT&CK into their products. This, combined with the industry’s focus on adversarial techniques and red teaming along with the investment on the MITRE side into user education, has made this framework a go-to in security.
Sadly, there is more to security than what MITRE ATT&CK covers, and that’s where we still have plenty of gaps. Many people aren’t aware but MITRE itself has gone beyond ATT&CK - it also introduced the Common Attack Pattern Enumeration and Classification (CAPEC) for application security. MITRE offers a comparison between these two frameworks and a guide on when to use which one. In general, I think we are in a good spot when it comes to codifying adversarial tactics and techniques.
The second step is to codify the countermeasures defenders can employ to prevent malicious attacks (the cyber equivalent of the procedural codes). There is good and bad news here. The good news is that MITRE has developed D3FEND, a knowledge graph of cybersecurity countermeasures. The bad news is that it’s not nearly in the same spot as ATT&CK and it has not seen adoption at a comparable scale. There are many reasons why that could be the case. First and foremost, security has strong roots in breaking things so red teaming, identifying gaps, and finding ways in is what most people in the industry are drawn to. Defensive mapping is both less exciting and much harder since it requires organizations to have a deep understanding of both their existing defenses and the specific techniques they want to address. MITRE D3FEND is harder to implement since unlike ATT&CK which can be used for red teaming and understanding threats, D3FEND feels much less hands-on and practical.
By combining both ATT&CK and D3FEND, security practitioners and cyber insurance underwriters should be able to get a better understanding of what controls work. What D3FEND needs is more depth. As the cyber insurance industry matures, it is getting better about the data it is able to gather. Several years ago, an insurance questionnaire would just ask “Do you have MFA enabled?”. Today, we go a level deeper - “Is it enabled for cloud access? Remote access? Email access? Privileged access?”. We aren’t still getting the full context (I.e., “Is it all of remote access?”) but we are on the right path. For D3FEND to be actionable, it needs to cover more depth so that we can see how much of a difference having MFA makes if it covers email access for all employees vs. some, if it covers cloud access but not domain admins, and so on.
The last two bits of data are needed for us to develop a standardized classification in security, namely security capabilities offered by different tools (the cyber equivalent of the pharmaceutical codes) and ways to describe where the attacks are observed (the cyber equivalent of the topographical codes) are valuable even if they in part overlap with the former two. Developing a cyber equivalent of pharmaceutical codes would be especially interesting since we all know cybersecurity marketing has gotten out of hand. I wouldn’t be overly optimistic here since MITRE has demonstrated that Goodhart's Law is real (“When a measure becomes a target, it ceases to be a good measure”).
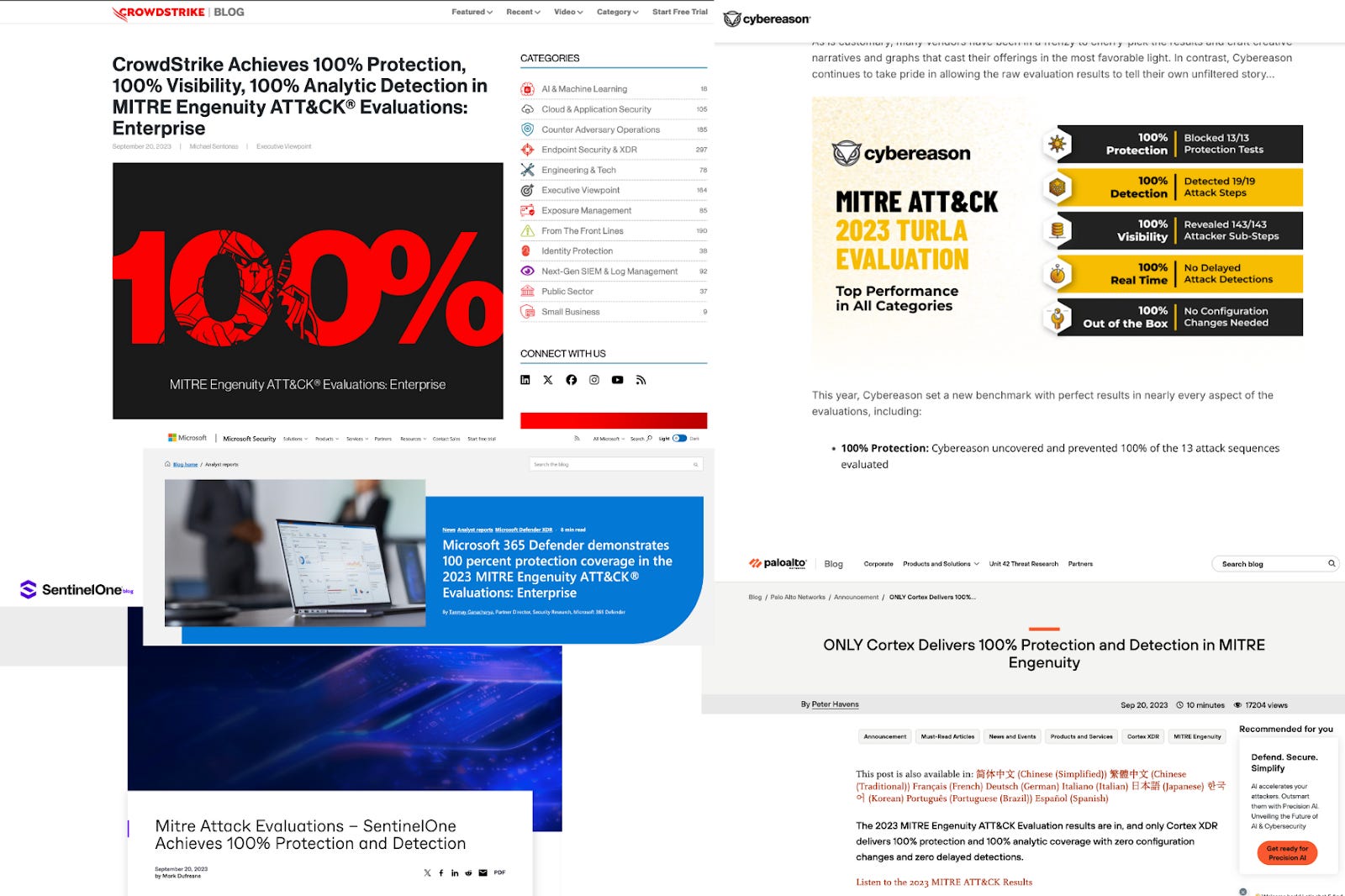
Image Source: CrowdStrike, Microsoft, Palo Alto, SentinelOne, Cybereason
I think MITRE would be the best stakeholder to drive the initiative to bring medical coding into cybersecurity. They’re more than halfway there, they have the right talent and a lot of trust credit in the industry.
The bad news is that we need to design incentive systems to get the data
The reason we are able to generate instant quotes about life, auto, or fire insurance, is the fact that there is plenty of data available in the public domain to calculate rates. This is because of the way the data is being collected.
In case of a burglary, victims will first have to file a police report in order to submit a claim to their insurance company. When an office catches fire, building management will need to call a fire department before they can file a claim with their insurance company. When a person needs medical attention, she will go to a hospital or urgent care facility where medical staff will independently assess the injury. In each of these cases, someone other than an insurance company is first to capture the data about an incident. The challenge is that there is no such entity with cybersecurity. Although both a burglary and a cyber attack are crimes punishable by law, police don't usually get called when there is a ransomware event. Therefore, there is no public record of a breach, and no data makes it to the government for analysis.
With many types of incidents, the government has had decades to establish its own ways of data collection - it doesn’t need to rely on insurance for basic data gathering. Cybersecurity, on the other hand, is so new that we simply don’t have anything in place. Imagine if health agencies had to ask insurance companies to share data because hospitals would refuse to share records citing “data sensitivity” as the reason why. It sounds odd to even think about it but that’s exactly what we are doing with security.
Solving this problem is not easy but we can get creative. It would be great if the government mandated that in order for insurance companies to be able to adjudicate claims related to a security breach, this breach would need to be first reported to some independent entity such as CISA. This is no different than many other types of insurance. In order to claim that a car was stolen, a person would need to provide evidence of a police report. The problem is, that the federal government in the United States doesn’t have the authority to regulate insurance, and convincing all 50 states to agree to something is simply not realistic. Maybe, the National Association of Insurance Commissioners could implement a model rule making that a requirement. Today, we simply don’t have any access to the security incident data which is hidden away from public eyes citing attorney-client privilege. Even the SEC requirement to report “material” security incidents is based on the ambiguous criteria of materiality. Imagine how much less ambitious it would be if companies were asked to disclose any security incidents for which they were seeking coverage from their insurance carrier (how is that not a common definition of what’s material?). I don’t believe in excessive regulation and I think we should be more creative when looking for ways to get what we need, putting incentive design above mandatory rules. That said, regulation does work so until there are better ideas, we can start with that.
Closing thoughts
I am not the only one who thinks that cyber insurance has the potential to move the cybersecurity space forward. I am not, however, a believer that insurance companies are going to start diving deep into every company’s security controls. This is because:
Insurance is still a business, and insurance companies want to issue policies so that they can make money. Customers have plenty of options in the market, and if one insurance provider starts asking them to fill out hundreds of pages of questionnaires, deploy something in their environment to test their security posture, they will just go to the competitor that won’t have any of these obstacles.
Security maturity is much more about the mindset rather than the presence of specific tools, or a number of controls. Any company that has architected its defenses in a way that addresses its unique environment and threat model, will have a stronger security posture than someone who spent millions of dollars to buy a bunch of “best of breed” tools but hasn’t properly deployed or configured them.

Image Source: IMBC
D3FEND is certainly a good starting point and to measure Security controls in the field.
When we take tools, processes and people into the equation, I'm a big fan of the SIM3 v2 Assessment by the Open CSIRT foundation: https://sim3-check.opencsirt.org/#
Ross...
You were probably in grade school when I had this exact same conversation for the first time in 2008 or so. It isn't a hard problem btw but a large part of the issue is the historical data which is so valuable is not structured and normalized properly in order for this type of use. Much of the underwriting data such as the qual/quant is soft data in application forms and claims files that is not easily extracted.
The data is actually not complex or difficult to model at all. The hard part is getting industry to build a standard after AC$$D is no longer trusted by many including me. I can build a base model in a few days and have built three insurance standards. But where do we go? There has to be a caretaker organization.
Mica