


Security is about data: how different approaches are fighting for security data and what the cybersecurity data stack of the future is shaping up to look like
Looking at different players promising to solve the security data problem, what each of them brings to the table, and the trends defining what the cybersecurity data stack of the future is going to be

Welcome to Venture in Security! Before we begin, do me a favor and make sure you hit the “Subscribe” button. Subscriptions let me know that you care and keep me motivated to write more. Thanks folks!
Nearly everyone these days is repeating the same mantra - “security is about data”, yet few people realize to what degree this is true. Some parts are obvious: unless we can properly collect and operationalize events and telemetry, we cannot receive an alert notifying us that there is a threat, or do a retroactive hunt and figure out that our organization has been compromised months ago. Other sides of the story about the importance of data are less straightforward, for instance, the degree to which companies that store data - cloud providers and data lakes - have the power to define the entire security value chain.
In this piece, I am looking at security data, trends that define its state, different approaches fighting for the ownership of data, and what the future could look like.
This is version one of a series of articles - and I am sure as I learn more, there will be a second and likely a third deep dive. There are many more approaches, perspectives, and ideas about data than I can describe, so I fully intend to refine my understanding as time goes by. For once, I am quite curious about the future proposed by Avalor, an Israeli cybersecurity startup that came out of stealth earlier this year, and a US-based RunReveal that appears to challenge the traditional SIEM market with some of its recent announcements. It is also worth saying that I am not attempting to create a market map and all vendors called out in the piece are for illustrations only (there are certainly many more companies than I featured here).
The importance of data in security, and the concept of data gravity
Data is central to security: without reliable access to security telemetry, organizations cannot understand if their stack is correctly configured, detect threats, or retroactively hunt for security incidents, to name a few. One of the biggest challenges security teams run into is deciding what data to collect, what data to store, and for how long. The struggle is real: security practitioners never know how long it will take them to figure out that their organization has been breached. If they ever need to go a year or two back, they need to have the data to re-create what happened, understand the full scope of the impact, and remediate the incident. Since it’s not possible to predict what data the security team will need a year from now, a simple answer is to collect everything and store it for as long as possible.
This ever-growing need for storing massive amounts of data created an opportunity for a wide variety of vendors to step in and offer their approach to data collection, aggregation, storage, retroactive threat hunting, detection engineering, and other problem areas.
Before we begin, to be able to run thought experiments and think about the future of cybersecurity, it is critical to understand the concept of data gravity. Rather than explaining it from scratch, here is an excerpt from one of my previous articles on this topic: “The idea [ of data gravity ] was first introduced in 2010 by Dave McCrory, a software engineer who observed that as more and more data is gathered in one place, it “builds mass”. That mass attracts services and applications, and the larger the amount of data, the greater its gravitational pull, meaning the more services and applications will be attracted to it and the more quickly that will happen.
Data gravity leads to the tectonic shift in cybersecurity: security data is moving to Snowflake, BigQuery, Microsoft Azure Data Warehouse, Amazon Redshift, and other public and private cloud options. As the amount of data increases in size, moving it around to various applications becomes hard and costly. Snowflake, Google, Amazon, and Microsoft understand their advantage incredibly well and are taking action to fully leverage it. As it relates to cybersecurity, they typically do it in the following ways:
By offering their own security services and applications, and
By establishing marketplaces and selling security services and applications from other providers.” - Source: Security at the source: “data gravity”, data warehouses, and cloud providers
From legacy to modern approaches to security data
Traditional SIEM approach: send us all of your security logs to one place and keep them locked in our ecosystem
When we hear “SIEM”, we typically talk about the traditional security information and event management vendors which offer organizations tools to:
Centralize all security logs in one place
Correlate events and telemetry from different sources to detect suspicious behavior
Query security data in real-time
Write custom logic to correlate detections. In its purest form, a SIEM is not a source of detections, it is an aggregator: the value comes from being able to correlate detections from across different detection sensors to be able to detect attack chains or related alerts.
Overall, it is the place where security analysts can do most of their work making sense of what’s happening in the organization’s environment, and where many CISOs and security managers run their compliance reports.
The original SIEM tools were designed for a world where organizations had a small set of security technologies in a few places, and they needed the ability to collect, aggregate, and correlate data from these tools. That’s not the world we live in today with the ever-growing scale, increasing number of sources generating telemetry, and consequently, previously unimaginable amounts of data.
As more and more data was sent to SIEM, vendors realized their power and understood that switching costs had become so high that customers had no choice but to continue sending data to the same place. Armed with this realization, they started increasing prices - at first gradually and then so drastically that an initially small percentage of security budgets spent on SIEM has been going up considerably. What feels like overnight, security teams were faced with the dilemma: since they could no longer afford to collect all logs and send them to the SIEM, they needed to somehow find a way to prioritize what telemetry they needed - a task that as previously mentioned, is unsolvable. Another problem that needs to be answered is how long to store the data. SIEM solutions are quite good at short-term retention, but after 30-60-90 days, telemetry storage becomes nearly fully unaffordable. The hot/warm/cold storage that emerged from this is also just a band-aid and not fixing the underlying problem.
The more time the security teams would spend looking for ways to reduce cost, the more apparent the extent to which they are locked into their tooling would become. Not only is it expensive to move data from one tool to another, but the fact that each vendor has its own event taxonomy makes it incredibly hard to accomplish. To address this challenge, cloud providers & data lakes have started offering alternatives to SIEM - ways to centralize large volumes of data, analyze it at scale, and access cost-effective long-term retention.
Traditional SIEM solutions have several shortcomings that are starting to feel more and more acute, including:
The power and the convenience of relying on SIEM connectors means that all data ends up in the SIEM even if it’s not the best option for this particular type of telemetry. Since customers aren’t able to easily ship their data to a different destination, vendor lock-in is inevitable.
The ever-growing exorbitant cost of long-term data storage and the challenges this creates (the need to decide what data to store, the inability to do retroactive threat hunting because of the absence of old data, etc.)
The problem of scale - traditional SIEM products were built on top of a legacy database or document-oriented search engines, such as Elasticsearch. These solutions don’t typically scale well for analytical workloads; although to a degree that scale can be accomplished, it is cost-prohibitive for many enterprises.
The fact that security data is siloed from other business data leads to inefficiencies and forces other teams to re-ingest the same data to their solutions of choice creating duplication of data and incurring additional charges.
SIEM was created for storing and analyzing logs. As we generate more and more heterogeneous (different types of) data, logs are turning into a small part of what a security solution needs to process and analyze. With the advances of AI and the rise of LLMs, we learn that unstructured, free-form data such as online reviews, user feedback, and social media mentions can also be analyzed to extract valuable security insights. Similarly, graph data is inherent for representing threat actors and behavioral user and asset relationships. All this cannot be done in the traditional SIEM paradigm.
Locking the data in a closed SIEM ecosystem makes it inaccessible for data analysts and engineers who are unable to use their preferred tools to make sense of data at scale.
This last part, namely the inability of detection engineers, security engineers, and data science practitioners to come in with their set of tools and start working with data is becoming more and more critical. The traditional SIEM solutions haven’t been built with advanced use cases in mind, and any company that has a mature security team, or forward-looking security leadership knows that “freeing up” the data from a locked-up SIEM ecosystem is the first step to advancing the craft within the company.
Today, modern organizations are increasingly able to solve their problems better by separating data collection, data storage, and data analytics, as well as experimenting with other technical possibilities and approaches, but none of that is possible if the security team solely relies on SIEM where connectors and analytics are tightly coupled.
Another factor worth mentioning is the push to centralize the business data. Over time many organizations understood that there is no such thing as “security data”, “marketing data” or “financial data” - there is business data that needs to be accessed and analyzed from different angles and by different teams; security is just one of many use cases. The larger the organization, the more likely it is that different departments will have different data needs. It became apparent that letting individual teams isolate “their data” in separate domain-specific tools is solving problems in some places but introducing them in others. When there is no centralized monolithic data strategy, the same data gets duplicated across different tooling. This not only leads to inefficient decision-making but also results in unnecessarily high costs because the same data is stored in many locations. It’s worth noting that not all reasons for data duplication can be eliminated: data sovereignty and data residency constraints, for instance, mean that companies may still have to duplicate a large part of their data in order to comply with regulatory requirements.
Despite all this, SIEM vendors have been able to protect and even solidify their position in the market. Reasons are plenty but the main one is vendor lock-in and the resulting lack of decoupling in data acquisition and subsequent analytics. The amount of effort required to move from one tool to another - re-configuring all data connectors, building new detection content, learning new syntax and new shortcuts, adjusting to the new web app experience, migrating existing playbooks, and the like - makes it feel like an insurmountable task. Those teams that decide to go ahead regardless, are hit with the reality when they get an estimate of what it will cost to export their data from their old proprietary SIEM solution and import it into a new one.
Splunk
Splunk undeniably remains the strongest leader in the SIEM space, beloved by many analysts all over the world. This isn’t accidental: Splunk provides user experience that works for security analysts who are not data engineers. One might argue that over the years, the company has shaped the security practitioners’ understanding of what it means to be a security analyst and the customers’ expectations when it comes to SIEM products. To further solidify its position as a market leader, Splunk has heavily invested in its app store and incentivized developers to build on the platform, thus creating a rich marketplace with a lot of content.
Despite such market acceptance, it comes with several serious challenges. First and foremost, Splunk is expensive - that is prohibitively expensive, especially if an organization is looking for long-term retention. This makes some use cases such as retroactive hunting outright impossible for many security teams. Second, the company has had challenges porting its on-premises solution to the cloud. Buying the cloud version from Splunk is expensive, and running it yourself is also costly as the compute hasn’t been well optimized.
As the number of companies dissatisfied with the way Splunk has been trying to aggressively increase its prices grows, it may be tempting to picture a massive exodus of customers from the platform. This process is likely to be much slower: Splunk is still one of the best-known tools on the market, and the nature of the data gravity effect makes it hard for companies to switch after they’ve invested so much into the tool. Moving data, and even more so - dashboards, queries, detections and correlation rules - is incredibly hard and time consuming.
A note on Splunk acquisition
Coincidentally, just as I was reviewing the final draft of the article, an announcement came out that Cisco is buying Splunk in a $28 billion cash deal, which makes it the biggest security transaction ever. I could say a lot on this topic, but I won’t because Jake Seid, co-founder and General Partner at Ballistic Ventures did that for me. In his LinkedIn post, Jake concludes:
“Largest acquisition ever by Cisco is in #cybersecurity with #splunk but IMHO here's why I don't agree with it:
We're at the start of fundamental re-plumbing of the data infrastructure in large enterprises.
There will be significantly more corporate data than security data. As a result of this and the re-plumbing, security data will ultimately ride on the same hyper-efficient infra that houses the 10x+ more corporate data. Security data won't live in its own silo.
This is not only about efficiency but also about being more secure.
When it comes to being more secure, I believe the trend will be that you have to "zoom out" on data that feeds security analytics. Gone will be the days where you're applying security analytics to just your security data silos. To improve security, you need to apply security analytics to all your stores of data with this "zoom out" mindset including the much larger corporate data sets. This is going to be enabled by the fundamental re-plumbing of enterprise data infra that's happening now.”
I agree with his take. Security data is not a separate kind of data - it’s business data used for security use cases. Keeping data in a silo for the use of one department isn’t what the future looks like.
Data lakes: don’t silo your security data
A data lake is a way to store and process large amounts of original (raw) data that is too big for a standard database. Data lakes evolved from data warehouses and removed the need to pre-transform data for it to be analyzable. Rather, data lakes operate on top of low-cost blob storage and allow for scalable execution of various workloads. Security, as usual, is lagging behind in the adoption of this approach. Unlike SIEM tools initially built for managing logs, data lakes were designed to store any kind of data, structured or unstructured, at scale and in a cost-efficient manner.
There are many use cases for data lakes in security, including:
Cost-effective long-term retention - something that hasn’t been possible with traditional SIEMs
Centralizing security telemetry to enable correlation and behavioral detection, retroactive detections, etc.
Infinite scale - reducing the need to worry about scaling capacity and increasing the storage space
The ability to keep security data with the rest of the business data, making it accessible to other departments such as business intelligence and reducing the need for duplication
Enabling advanced data science use cases that are not possible in the traditional SIEM paradigm
Data portability - the ability to move from one vendor to another and keep the data where it was before (in a data lake). Modern organizations want the inverse relationship: keep that data in their lake, and then make it accessible for multiple vendors, rather than copying/moving it over to them; admittedly, the vendor landscape isn’t there yet.
Fundamentally, data lakes solve a pile of business problems of which security is just one small part. The challenge is that most of the benefits data lakes offer come at a cost: companies need to have the right talent to fully take advantage of what data lakes can offer. Teams must think about their data strategy upfront and architect their solutions in such a way that maximizes the advantage of the models appropriate for different circumstances. For instance, it may be smart to keep some data on-prem, but when these decisions are made, it’s important to consider data availability that goes down when the data is not stored in the cloud.
The adoption of data lakes in security coincides with the maturation of the industry. Typically, companies start implementing data lakes when they are ready to hire threat hunters, detection engineers, and data scientists, and learn that new hires cannot do their best work using the tools most suited for the job when the data is locked in a SIEM (it’s not that it can’t be done, it’s more that it’s not sustainable and cost-efficient). The first step is often not about replacing a SIEM but about running two solutions - the legacy SIEM and the data lake in parallel (Anton Chuvakin wrote about running two SIEMs back in 2019). Over time, some companies end up adopting a data lake together with a New-Gen SIEM solution built on top of a data lake, or a separate analytics layer. This enables SOC teams to use the SIEM interface they are familiar with, and the data science team can directly access the data in the underlying data lake.
Another factor that is likely to accelerate the adoption of data lakes is the rise of AI and LLMs. As Tomasz Tunguz points out in his blog, historically SaaS applications were built on structured databases. Now that LLMs are gaining adoption with the promise of being able to process and learn from unstructured data at scale, a new generation of software-as-a-service providers will have no choice but to start leveraging this. Security teams and companies are not an exception: while before, they would primarily rely on logs and telemetry, the new generation of approaches and solutions will have the ability to make use of unstructured data. This trend will drive the adoption of data lakes as they are where unstructured data is most likely to be stored using the modern software architecture. This can be attributed to the underlying property of cheap blob storage: anything can be put in there, from structured parquet files to zip archives of images. The lake execution engine (that sits on top of the storage) just happens to have really good I/O-channels to the stored data, so it can process a lot at high speeds.
Next-Gen SIEM vendors: send all of your data, and we will store it in a data lake
Not everyone is going to build their own data lake with the proprietary SIEM-like capabilities on top. Another way for customers to achieve a similar outcome where their data ends up in the data lake is to leverage Next-Gen SIEM providers.
Traditional SIEM tools such as Splunk couple data collection, processing, storage, and analytics, which as I’ve discussed, lead to a broad range of challenges.

To address the shortcomings of the SIEM solutions, several new vendors appeared, including Panther and Hunters. Positioned as Next-Gen SIEM solutions, they were designed to push out the well-established legacy vendors by:
Offering their customers control over their data. Next-Gen SIEM vendors are built on top of data lakes, so the data they store is no longer siloed and locked in proprietary tools. This makes it possible for customers to free themselves from vendor lock-in.
Enabling customers to access cost-effective long-term retention. Storing data in data lakes is significantly cheaper than doing it in traditional SIEMs such as Splunk.
Making it possible for customers to mature their security approaches. The same data can be accessed by data analysts, security engineers, and others directly from the data lake, while SOC teams can use the SIEM interface they are already familiar with. This unlocks new possibilities organizations could not even think about before.
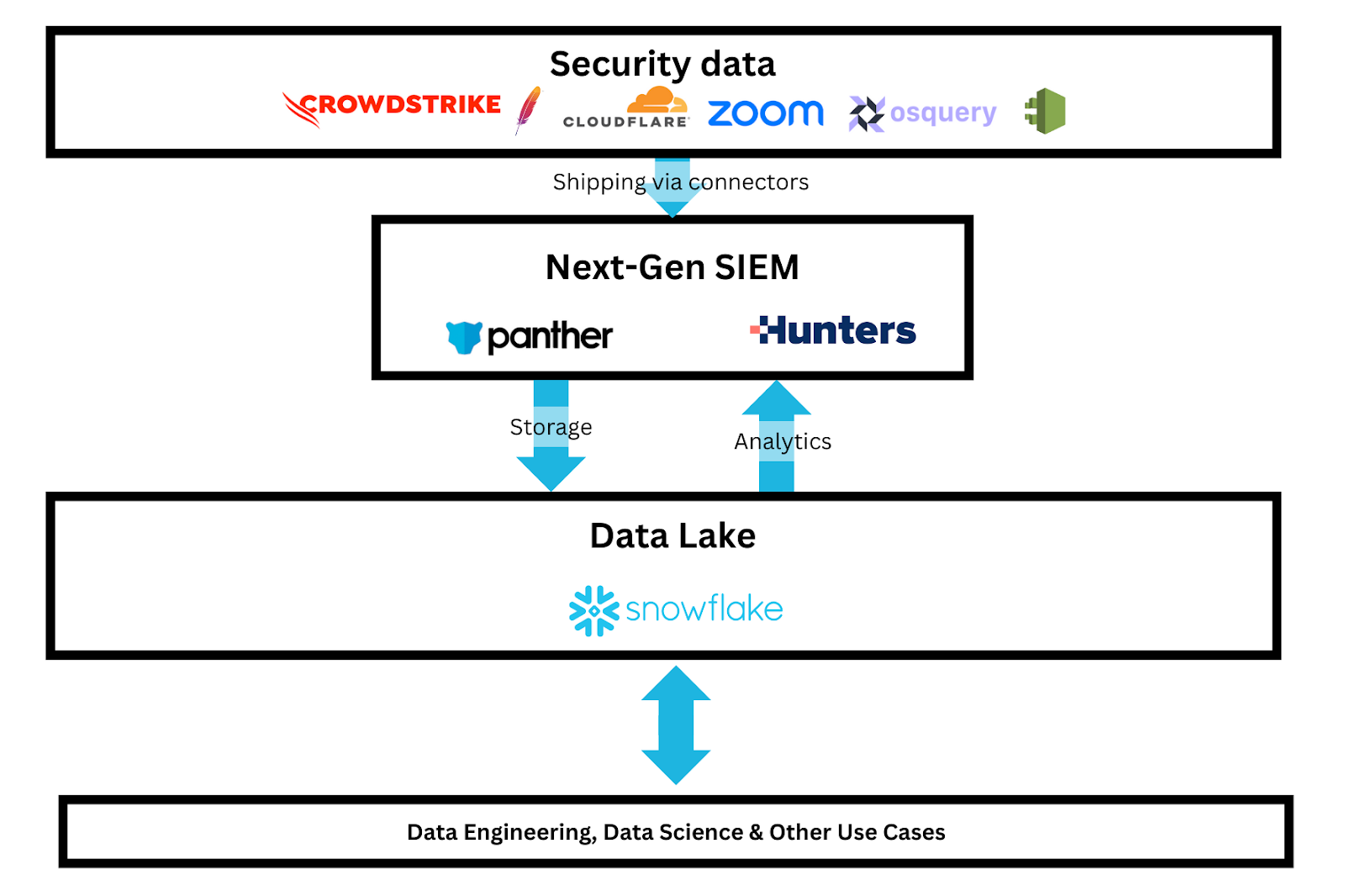
That is not to say that Next-Gen SIEMs solve all problems. For starters, on the fundamental level, they are still SIEM solutions, which means that they require all security data to be ingested into the product via connectors. This is noteworthy: as long as the data goes through the SIEM vendor at ingest, it'll be an opportunity for the vendor to introduce complexity (the truly open SIEMs can be adapted to work with data that users have provided through a side channel). Moreover, Next-Gen SIEMs are pretty low on "native" connectors so security teams often have to build and maintain a lot on their own. Second, before the data can go to the SIEM-managed data lake, it often needs to be dropped to S3 for the vendor to pick up (so customers are paying for storage twice). Third, Next-Gen SIEMs demand that companies that adopt them have a larger level of security maturity compared to the users of legacy products; while this shift is fantastic over the long term, it does require some investments from organizations in the near term.
To compete with traditional SIEM vendors, the New-Gen providers need to have a lot of capital. Building a SIEM is a very heavy effort in terms of research & development (R&D), and legacy behemoths like Splunk have raised the bar of customer expectations quite high. A new entrant is always faced with the pressure to be “at least as good” as Splunk, which is quite hard to do unless the company has raised a lot of money. Startups that do attract large checks from investors at high valuations are faced with another dilemma: the aggressive expectations for revenue growth that are incredibly hard to meet in a highly competitive, “red ocean” market.
Another challenge of trying to displace traditional SIEM solutions is that organizations rely on these vendors for more than some practitioners realize, including:
Detection content: relatively few companies have the talent, resources, and know-how to write their own detections. The ability of Splunk and other traditional SIEM providers to leverage threat intelligence and build detection coverage is a significant factor that keeps customers stuck with the expensive vendor.
Compliance reporting: centralizing all data to see if they are NIST compliant, etc.
Internal reporting: reports for different stakeholders (legal, compliance, risk, executive team, etc.)
Next-Gen SIEM providers, to get the chance to displace legacy SIEMs, often need to initially convince organizations to implement them in parallel with their main SIEM. The idea is that over time, as new solutions mature, they can replace the legacy product entirely, but to start, they will be adding value by solving problems that the main SIEM does not. For instance, a SOC may be using the legacy SIEM, but threat analysis and custom models would be done in the data lake - and the Next-Gen SIEM used as an interface to the data lake. Running several tools in parallel is not easy, especially given how many organizations are trying to reduce the number of security tools they rely on. Worse yet, no security team is looking forward to the situation when they need to run a big investigation across two tools.
Panther
Of all the companies in the Next-Gen SIEM space, the one I find most interesting is Panther. Panther started by targeting cloud-native, highly mature security teams from venture-backed, Silicon Valley-based enterprises looking for the ability to fully own their security posture. Security teams with strong proficiency in Python could do a lot with the product, the only challenge is that the number of organizations where security has embraced an engineering mindset outside of California isn’t as high as many of us, including myself, would like to see. Panther recently started to look for ways to broaden its total addressable market and released a no-code detection engineering experience targeting those who aren’t as savvy and well-versed in Python.
The product offers a modern approach to security with detections-as-code, the ability to have full visibility into detection coverage, the ability to get started with a pack of pre-written detections, etc.
Sentinel and Chronicle
Chronicle & Sentinel are interesting solutions as they exist at the intersection of SIEM and data lakes, and they have both done reasonably well. As a child of Google X, Chronicle leverages Big Query to provide a managed data lake while Microsoft’s Sentinel stores data in Azure Monitor Log Analytics workspace. Both solutions offer detection content and support advanced use cases, although they don’t provide flexibility in deployment (it’s Microsoft for Sentinel and Google for Chronicle).
The main advantage of SIEMs built by cloud providers is that the data doesn’t live within a SIEM - it lives within the cloud storage offered by the provider. This makes it possible to access the data through the SIEM for the needs of the SOC, and leverage access to the same data outside of the SIEM for data analytics, data engineering, and other use cases. Another advantage is cost. Chronicle SIEM, in particular, has a very customer-friendly billing: its pricing is based on either a per-employee or ingestion model and includes 1 year of security telemetry retention at no additional cost.
SecOps Cloud Platform approach
LimaCharlie’s SecOps Cloud Platform offers another approach to security and security data. I run product here at LC so naturally, I find it hard to be fully unbiased about what we do.
While data lakes put the needs of data engineers and data scientists front and center, LimaCharlie focuses on the needs of security engineers and SOC (Security Operations Center) teams. The company builds security capabilities designed to interoperate in an un-opinionated way that can be arranged by security teams to address specific use cases they need, from log forwarding to detection and response, incident response, building security products, etc. This approach is often described as “Lego blocks for cybersecurity” and is similar to that of AWS which instead of offering boxed products, provides a set of “primitives” that can be built on and used however it makes sense for the specific organization.
The product offers a modern approach to security with detections-as-code, the ability to have full visibility into detection coverage, the ability to get started with a pack of pre-written detections, etc.
LimaCharlie doesn’t attempt to replace the need for data lake but the exact use case will naturally depend on the organization. Instead, it offers security teams a powerful platform for detection, automation, and response, provides one year of security telemetry at no extra cost (similar to Chronicle), and offers the ability to consolidate security data and send it where it should be (similar to Tenzir and Cribl).

Source: LimaCharlie
The importance of content for the adoption of data lakes, Next-Gen SIEMs, and the SecOps Cloud Platform approaches
Initially, the main obstacle to the adoption of data lakes, Next-Gen SIEM solutions, and the SecOps Cloud Platform approaches was the fact that they didn’t come with content. This was indeed a challenge: most security teams do not have the talent and the resources to do threat research and build their detection coverage. While many do have the ability to add their own detection logic on top of that offered by the vendors, relatively few (top 1-5% of the most mature security teams) can fully rely on their own content alone.
If this problem wasn’t addressed, it is likely the new approaches to security data would not gain as much traction as they did. But, where some see an obstacle, others notice an opportunity. Today, we see the emergence of the market fully focused on security content. Three of the most notable startups in this space, SOC Prime, SnapAttack, and Cyborg Security enable security teams to get comprehensive threat detection coverage for their data lake, Next-Gen SIEM, or the SecOps Cloud Platform without having to write their own detections. The public Sigma rule repository contributes significantly to the detections shared by the content providers highlighted before. This emerging ecosystem of threat detection content providers combined with the new approaches to data enables enterprise teams (security, data science, etc.) to focus on what they can do best - security and analytics instead of managing their infrastructure.

Decoupling of data processing, storage & analytics into separate layers
Each department within an organization needs different granularity, and different insights, and has a different purpose for their analytics. The IT team will interface with data using their application of choice, while security, business intelligence (BI), marketing, data analytics, product, and other teams will choose tools that make sense for them. However, since it’s still the same data, the question becomes how can we centralize the data but enable different teams to use their preferred tooling to analyze it. The decoupling of storage & analytics into separate layers is a trend that emerges as an answer to this need.
Omer Singer of Snowflake explains this trend quite well in one of his LinkedIn posts.

Source: Omer Singer on LinkedIn
Anvilogic
Anvilogic is a solution that best represents the evolution leading to the split of the analytics layer of security. Anvilogic’s SIEM-less architecture lets organizations leave their data where it is while still taking advantage of security analytics capabilities — effectively decoupling the data storage layer from the analytics layer. The product was built on the premise that bringing all the data to one place is very hard for enterprise companies to do. They can’t rip and replace their existing tech stack and send the data overnight to a data lake - they need a path to get there often starting with a few data sources at a time. Unlike smaller, cloud-native companies that tend to have small, highly technical teams where it’s easier to send all of their data to one place (a modern cloud-native SIEM), larger enterprises are much more complex and the data itself is located across many different solutions, often as a result of mergers and acquisitions (M&As), data residency regulations, and the like. The large number of tools, long backlogs of data sources that need to be integrated, the problem of data normalization, and internal politics create a massive pain for security teams.
Anvilogic offers a modern approach to security with detection-as-code, 1500+ pre-built detections, the ability to have full visibility into detection coverage, and a no-code detection builder, but unlike a next-gen SIEM, they allow customers to leave their data where it is rather than require all security data to be ingested into the product via connectors.
Anvilogic states that security analytics needs to occur regardless of where the data is stored - a database, a data lake such as Snowflake, a traditional SIEM like Splunk, a cloud provider such as Azure, or some kind of logging platform, and most importantly the customer doesn’t have to be restricted to one. The company is not trying to fight current complexity when enterprises rely on a SIEM, data lakes, and other solutions at the same time, but embraces it. By providing a consistent analytics layer, Anvilogic makes it possible for security teams to slowly shift from a SIEM to a data lake like Snowflake if they choose to do so, and do it without disrupting their processes: the data is still being queried (in the native language of its location) and triaged in the centralized location, the results from the queries will be consistent (enabling ML use cases like alert tuning and threat hunting), and customers can still integrate with their automation tools & any other downstream case management systems that they already purchased.

Decoupling data acquisition from downstream processing & storage
One of the most important trends in the security data world is decoupling data acquisition from downstream processing, storage & analytics. Historically, all security data was sent directly to SIEM. As we’ve discussed, there were several reasons for it:
The idea of creating “a single pane of glass” - one place that gathers all security data from across the organization
The need for a centralized correlation and detection engine
The fact that SIEM vendors invested in building data connectors - tools that greatly simplified the collection of data from different sources and its normalization to a common format
These factors led to the strong data gravity when security data was sent to a SIEM whether or not it needed to go there. And, once all data was in SIEM, it made sense to implement a wide variety of use cases directly within SIEM, even if it wasn’t always the most effective or the most cost-efficient place.

As security organizations matured, several things became apparent, including:
Shipping all data to a SIEM via connectors leads to vendor lock-in; security vendors know about that and actively take advantage of it.
Having more security data in the SIEM doesn’t help security teams make better decisions unless that data is being actively used for real-time detections, alerts triage, false positives elimination, etc.
Sending all security data in one place doesn’t necessarily result in more efficiency if security teams don’t know what to do with all that data.
Some security data is better stored in more cost-effective locations, especially if it doesn’t need to be frequently retrieved and analyzed (such as storage for compliance purposes).
Despite a long list of factors impacting the trend, decoupling data acquisition from downstream processing, storage & analytics has been primarily driven by two constraints - the desire to eliminate vendor lock-in and the need to cut costs. More and more organizations come to realize that by adding something in front of a SIEM, they can decide what data needs to be sent and where. In other words, while some data such as security alerts would still go to the SIEM, logs and telemetry not needed there could be stored in a data lake or other cost-effective storage.

The time when companies would be looking to send all of their data to one place, without considering what it will be used for, how long it needs to be stored, and so on is over, in large part thanks to solutions that enable customers to control where they want to send their data.
This approach doesn’t suggest that security teams should stop using what they’re already using (say, a SIEM) or start deploying something new (say, a data lake). Instead, it promotes the idea that different types of data have different retention, analysis, and storage needs, and even more so - different uses, and different lifecycles. Customers don’t need all their data to be hot and searchable at all times. Some of the data can be stored somewhere cheap (Azure, S3, etc.) and accessed only when the company needs it for a fraction of the cost compared to the SIEM storage. Just because an organization has a SIEM, it doesn't mean it needs to send all security data into a SIEM:
Telemetry needed for correlation, may still be sent to the SIEM
Data that needs to be stored for years to come for compliance purposes may be more suited to be sent to cloud storage
Some granular security data (such as the number of incidents) may need to end up in some BI (business intelligence) tool
The granularity can also be fully customized: say, there is one particular verbose event type that needs to end up in tool X and never hit a SIEM - this can be easily configured with data routing solutions.
Even before the data can be sent to suitable destinations, it needs to be collected and normalized. These use cases - data collection, transformation, and loading are being addressed by a wide variety of solutions, most of which take a slightly different approach. Although these tools today are focused on moving the data from point A to point B, it’s obvious that many have much bigger ambitions. One can see a path to a data lake: once they have all data in a unified schema (say, open standards like ECS and OCSF), and given that they get to suggest where to move the data, it’s logical they would be looking to help guide users to their own data lake solution. Many startups are seeing the opportunity to insert themselves in the middle of the data movement and evolve their solution into a data lake but few understand that getting people to switch from their current solutions and achieving a product-market fit in this area is incredibly hard.
Cribl
Cribl, a US-based company that pioneered and instantly became a leader in the data routing & forwarding space, did so particularly with a focus on Splunk users. Cribl has several product offerings, but the one it initially became famous for is Cribl Stream, a vendor-agnostic observability pipeline that gives customers the flexibility to collect, reduce, enrich, normalize, and route data from any source to any destination within their existing data infrastructure.
Tenzir
Tenzir is an open-core solution providing data pipelines for the collection, normalization, processing, and routing of distributed and high-velocity security data. Users can deploy multiple Tenzir nodes and run pipelines between and across them to transport data between a variety of different security and data technologies. Security teams can put together sophisticated pipelines simply by using a library of modular building blocks called operators, similar to writing bash or powershell commands. Pipelines can process streaming and historical data. Pipelines are written in the Tenzir query language that includes security-specific data types and operations. Sigma and python code can be applied directly to data traversing pipelines, in addition to enriching event data with threat intelligence. The solution has a strong focus on data privacy and sovereignty, and allows users to federate search and detection by pushing queries to the nodes at the edge, and through pseudonymization and encryption. Cost management is another area of focus, including data reduction, aggregation and compaction, and consumption quantification and benchmarking. Tenzir's long-term vision is of a federated security data lake, promoting it as a cost-effective and sustainable architecture, built using open and industry standards to give users maximum control and ownership.
Substation
Substation is cost-effective, low operation ETL solution built for security teams to route & transform their data. As an open source project run by Brex engineers, it appears to be substantially more affordable than its commercial counterparts. Substation deploys unique data pipelines running on serverless cloud services that are managed using infrastructure as code.
Monad
Monad, a company that emerged from stealth back in 2021, built an ETL solution for security teams that facilitates the extraction of security data from a diverse array of security solutions, transforming it into a unified format before loading it to the chosen destination (i.e., Snowflake, Databricks). The transformed data can be structured into a Monad Object Model, OCSF, or a custom schema, offering a versatile approach to data management.
Tarsal
Tarsal is another ETL tool that makes it easy for organizations to collect security data from any source, normalize it to ECS, OCSF, or Tarsal's schema, and send it to the destination of their choice: Snowflake, BigQuery, Databricks, Splunk, Sumo Logic, etc.
LimaCharlie
LimaCharlie is a SecOps cloud platform that offers a broad range of security functionality including detection and response, security automation, one year of cost-effective full telemetry retention, and more. Among the capabilities LC enables, it also makes it possible to collect security data from different solutions, normalize it to a common format, and send it to the destination of choice.
Vector
Vector by Datadog is a high-performance observability data pipeline that enables security teams to collect, transform, and route all their logs and metrics with one tool.
Open source security lake platform
Matano, the open source security lake platform for AWS, was announced in early 2023. The company is a part of the YC W23 batch. In the announcement, after talking about the problems with legacy and New-Gen SIEM vendors, the founders explain how Matano works:
“Matano works by normalizing unstructured security logs into a structured realtime data lake in your AWS account. All data is stored in optimized Parquet files in S3 object storage for cost-effective retention and analysis at petabyte scale. To prevent vendor lock-in, Matano uses Apache Iceberg, a new open table format that lets you bring your own analytics stack (Athena, Snowflake, Spark, etc.) and query your data from different tools without having to copy any data. By normalizing fields according to the Elastic Common Schema (ECS), we help you easily search for indicators across your data lake, pivot on common fields, and write detection rules that are agnostic to vendor formats.
We support native integrations to pull security logs from popular SaaS, Cloud, Host, and Network sources and custom JSON/CSV/Text log sources. Matano includes a built-in log transformation pipeline that lets you easily parse and transform logs at ingest time using Vector Remap Language (VRL) without needing additional tools (e.g. Logstash, Cribl).
Matano uses a detection-as-code approach which lets you use Python to implement realtime alerting on your log data, and lets you use standard dev practices by managing rules in Git (test, code review, audit). Advanced detections that correlate across events and alerts can be written using SQL and executed on a scheduled basis.” Source: Launch HN: Matano (YC W23) – Open-Source Security Lake Platform (SIEM) for AWS
Companies thinking about building their own data lake may find using Matano a good idea: there is a lot of engineering work and challenges around architecting a data lake the startup has already solved. However, it remains to be seen:
How big their market will be given an even more technical nature of their product compared to solutions such as Panther, Tenzir, and LimaCharlie
If the company will be able to grow in the competitive market. Matano came out before Amazon announced its own security data lake - a solution competitive to what the company is offering (data lake for AWS). There is certainly a strong use case for the broader set of problems Matano is tackling, but it’s uncertain if customers will find the value proposition strong enough to adopt the solution. If Matano can offer a data lake on AWS that’s cheaper than that offered by AWS, it could be an interesting solution.
More granular solutions for smaller data-related use cases
Aside from large data platforms and core plumbing for modern security data stacks, there are smaller solutions designed to address specific use cases. Among many, there are three concepts I find particularly interesting: Query.ai, Dassana, and LogSlash.
Query your data across any of your existing security tools
The promise of Query.ai is simple: every security company has a large number of security tools and solutions each of which collects its own data. Instead of trying to send all of that data to one place and make sense of it in a centralized location, Query.ai proposes keeping the data where it is and offers a single search bar across all the security solutions. Query.ai appeals to security leaders in search of the so-called single pane of glass - one solution that unifies tens of disjoint security tools. It starts with one simple, well-scoped use case (search), but it’s easy to see how the product can expand into a broader solution for centralizing the security data.
The concept Query.ai proposes is simple yet powerful: a federation of security data. Some teams have learned that bringing all data in one place is both expensive and not easy to operationalize, so having a way to keep everything where it already is but also taking advantage of accessing data as if it was all centralized may be appealing to them. Based on the demo listed on the company website, Query.ai interfaces with existing tools, unifies the data flow in their engine, and normalizes it to the OCSF open event taxonomy format. Since it normalizes the data as it pulls it from separate tools, I imagine there would be a lot of computation that would need to happen, and that doesn’t come cheap.
The solution appears to be easy to adopt (come in, make no changes, and add Query.ai on top) which is both good and bad: it’s great because it simplifies the trial, purchasing, and implementation, and not great because it doesn’t deeply integrate with the security stack creating a moat, so it would be equally easy to stop using it.

While there are merits to this approach, I can see several challenges:
It may not solve the problems of compliance: not every product offers long-term retention sufficient to satisfy different compliance standards, so most companies will have no choice but to duplicate their data by sending it to a separate storage solution (cost-effective or not). Doing so may defeat having an additional unified search view.
It would be interesting to see what the performance of this kind of solution would look like. Pulling data from two or three tools at once and generating a chart may be easy. However, anyone who has worked in technology long enough knows that different solutions have different latency, throughput, quality, and limitations of their APIs, among other characteristics. While API-first vendors may very well have the ability for anyone to query their data at scale, I would imagine many security startups do not. The depth and breadth of queries that can be run would likely be limited by the lowest common denominator among the tools being queried. On the other hand, most security tools do have the ability for people to export their data or send it elsewhere where it can be accessed for further analysis.
There is more to security data than querying it. Security teams looking to do deeper research, big data analysis, detection engineering, etc. would still need to centralize their data and make it ready for analysis. Even more importantly, correlating security data is critical to be able to build behavioral detection logic and understand what one entity (user) is doing across endpoints, code repositories, cloud, and other areas. Without centralizing security data, it is not possible to correlate separate events and paint a full picture. Although this challenge isn’t impossible to overcome, it is definitely something to think about.
As an extension of the former, security teams can only search for known knowns - something they have an idea about, but want the ability to confirm. There are equally as many (if not more) known unknowns and unknown unknowns, and to spot these searching telemetry won’t help because nobody knows how to formulate questions (queries). Security teams need the ability to look through the logs, explore the story they are telling, and identify areas that look suspicious for further analysis.
Querying individual products at scale may result in usage charges within those products. Combined with the cost of computation, unit economics might not be easy to make work.
It may very well be the case that these are non-issues; I may end up updating the article as I learn more about the solution. Overall, I think the concept of federated security data will become more and more important, especially for large enterprises that cannot easily move their data into one place. The scope of what federated security data means, however, will vary: I can see how teams would be looking to query data located across cloud storage, a SIEM, and a data lake from one location. Having said that, I think that some form of centralization is inevitable; in other words, I find it hard to picture how security teams would keep the data inside separate security tools.
Based on the stated value proposition and the product functionality as described on the website, it’s reasonable to see how Query.ai can be a fit for security-specific workloads for security teams that are tools-focused, not engineering-focused. I think it would be great for security analysts yet it would likely make less sense to leverage it for data-heavy workloads requiring a lot of computing, aggregations, analytics, and detection engineering. In the long term, I’d imagine the product would mature and develop the ability to support more use cases. And, it’s not entirely unreasonable to see how Query.ai can over time become a much more robust solution, potentially even a data lake.
Prioritize your detections across all of your security tools
Dassana is a solution that helps security teams leverage their existing tooling. From the outside, it appears to be similar to several other tools I described before. What makes me mention it here is the idea of cross-tool prioritization of detections. Too often, when a security tool triggers a detection, it is prioritized relative to other alerts from the same tool. This may be a great way to do things in large enterprises where each area of security is owned by a separate team, but not for security teams that have a limited number of people working across a wide variety of tools. Dassana brings all the detections in one place and enables security practitioners to see the most impactful issues they can tackle organization-wide, not separately within each product (EDR, NDR, DLP, etc.). Similar to Query.ai, I imagine it would be a good fit for tool-rich companies with less of an engineering mindset on their security team.

Reduce the volume of logs without impacting the quality of data
LogSlash is a method for the reduction of log volume accomplished by performing a time-window-based, intelligent reduction of logs in transit. The inventor of this approach, John Althouse, explained how it works in the launch announcement: “It can sit between your log producers (e.g, firewalls, systems, applications) and your existing log platform (e.g., Splunk, Databricks, Snowflake, S3). No need to change your logging infrastructure as this is designed to slot into any existing setup.
With LogSlash, 10TB/day of logs flowing into Splunk can be reduced to 5TB/day without any loss to the value of the logs. LogSlash does this by performing a time-window based consolidation of similar logs using configurable transforms to retain what’s valuable to you.” The same announcement explains how LogSlash is implemented, and how it can be used for non-commercial and commercial use cases. LogSlash is effectively a set of aggregations - it’s useful to think of it as a set of SQL statements that help reduce log volume without impacting the quality of the data.
What I find particularly refreshing is that John’s invention wasn’t announced as a new startup launch - a point solution that has to be bought and integrated into an existing security stack. This illustrates that not every new idea needs to become a venture-backed startup and that some inventions are better shared in the field and left for commercialization to others (or made free in general).
Bringing it all together
The Theseus' paradox and why the SIEM is not dying
In cybersecurity, people often get too hung up on abbreviations, so one can regularly see statements like “SIEM is dead”, “XDR is obsolete” or similar. The letters change but the format remains - take an abbreviation used in the industry, declare it to be dead, and say that there is a better way of doing things.
So, is the SIEM indeed “dead”? With so much innovation, and so many new approaches and ideas, does this mean that there is no space for what industry analysts and buyers define as a “security information and event management” solution? The answer depends on how we interpret the question. If by “SIEM” we mean a specific product or a set of features that work a certain way, then it’s obvious that as one vendor loses its market leadership, another will take over, and the cycle continues. In this case, the stack of features we know today as “SIEM” will inevitably be obsolete as more companies embrace other approaches to getting value out of their data.
If we think about the underlying capabilities, the perspective shifts dramatically. As companies get rid of Splunk and similar legacy tools and move their data to data lakes and SecOps cloud platforms, they unlock new possibilities that were not possible inside their SIEM. However, they still need to support a lot of the basic functionality that the SIEM was handling well (think correlation, analytics, detection and response, reporting, and other basic security and compliance use cases). It follows that anyone replacing their SIEM needs to build the functionality that falls under two buckets:
Features that support the use cases the SIEM didn’t support
Features that support the use cases the SIEM did support
If a security organization chooses to rip out its SIEM and build the capabilities it needs on top of the data lake in-house, what are the chances that it will end up with something similar to Panther or Hunters, in other words, a SIEM? Oliver Rochford, Chief Futurist at Tenzir points out that this is the classic version of the Theseus' paradox. The paradox was first reported by the Greek historian and essayist Plutarch: “The ship wherein Theseus and the youth of Athens returned from Crete had thirty oars, and was preserved by the Athenians down even to the time of Demetrius Phalereus, for they took away the old planks as they decayed, putting in new and stronger timber in their places, in so much that this ship became a standing example among the philosophers, for the logical question of things that grow; one side holding that the ship remained the same, and the other contending that it was not the same”. In the context of SIEM discussion, the question can be phrased as follows: if the security team has ripped out the SIEM, implemented the data lake, and then built the capabilities they had in their SIEM on top of the data lake, is what they ended up with a SIEM?
Ronald Beiboer wrote an interesting piece earlier this year titled “SIEM is the new XDR” which shares largely the same idea and concludes as follows: “So, let's be honest, we are all building a SIEM. We are building tools on top of telemetry and logs from a variety of sources. We are all trying to automate stuff, integrate threat intelligence things, and make the lives of our customers easier and their environments more secure”. As a Senior Solutions Engineer at Splunk, he certainly has stakes in this discussion, but that doesn’t invalidate the core idea.

Image Source: Ronald Beiboer
I think as an industry, we would be better off if we stop focusing on abbreviations as much and think about the problems we need to solve. With SIEM or without SIEM, we need the ability to ingest, transform, route, process, store, and analyze data (structure and unstructured); we need to do it in a way that scales, in a way that gives practitioners full control over how its done, in a way that’s cost-effective, and in a way that doesn’t lock companies into one tool forever. If we change our approach to buying security capabilities, a few years from now it won’t matter if the SIEM is dead or if it’s still breathing.
Data gravity & building the industry on data lakes
With so much security data moving from one solution to another, the battle we are witnessing today isn’t one between traditional SIEMs and Next-Gen, cloud-native SIEMs; it is between different providers of modern data storage solutions, namely cloud providers & data lakes. Both leverage the previously discussed data gravity effect, so both want to see business data sent to them, and both are trying to offer more and more value to attract it.
Snowflake has emerged as a data lake with a large emphasis on security. It is eager to partner with startups building in the space, and by doing so it has diversified its bets across different versions of the future. For instance, both Panther, which stores its data on Snowflake, and its competitor Anvilogic, which adds an analytics layer to data stored in different locations, including Snowflake, are partners of the same data lake provider; so are Monad and Tarsal. Each of these parties is investing in thought leadership about the future of data lakes; Tarsal, to name one, has previously published a guide for companies about the best ways to gradually move to a data lake.
Any cloud provider or a data lake is happy to support companies looking to build on it; after all, they are happy as long as the data ends up in their ecosystem. What’s interesting about Snowflake is the niche it found in security and the passion with which it is trying to fill it.
Knowing that all major cloud providers have their own security solutions and by doing so they directly compete in the security market (the AWS is to a much lesser degree than the other two, but now it also has its data lake), Snowflake emerged as a platform upon which the security tools not owned by Amazon-Microsoft-Google can be built. The Next-Gen SIEMs - Panther and Hunters - are all built on Snowflake. Other solutions & approaches such as Monad, Tarsal, and Dassana, all mentioned in this piece, are also close partners of Snowflake.

It appears that the proposed future of the security data looks something like this:

The passion with which Snowflake is pursuing thought leadership in the industry is commendable. The RSAC 2023 conference was the first RSA where Snowflake had a presence. This was prefaced by a lot of social media posts, interviews, and content shared by Omer Singer across different channels. Surely, it’s hard to consider him fully unbiased, but if there is someone who deserves the title of an evangelist of security data lakes, it would be Omer. I’d highly recommend his interview from back in 2022 to anyone interested in learning about the data lakes paradigm. It remains to be seen how the industry develops, and to what degree data lakes will be able to deliver on their promise. That said, it is clear that the time of siloed security data locked in traditional SIEM solutions might be finally going away.
Unbundling, bundling & looking at the future of the security data stack
Security teams today are looking to get out of the vendor lock-in from their SIEM providers, delegating data acquisition, processing, routing, and analytics to different vendors. This isn’t unique to data-centric solutions, nor is it a cyber-specific trend: it is merely a manifestation of the industry-agnostic tendency in the technology space called unbundling.
Tech trends are cyclical, and unbundling is one of the two states of innovation; the other is rebuilding. In the years to come, as more and more enterprises adopt several solutions for different steps of the data value chain instead of the monolithic SIEM, companies building these solutions will try to offer more and more tools to centralize the data stack again. Although few founders are familiar with the concept of data gravity, most know quite well that if they can get customers to send data in their own data lake, the monetization opportunities are limitless. Anyone who controls where the data goes (ingestion, transformation & routing solutions), has the strong incentives and the power to suggest their own storage as the best option.

The more to the left (to the data ingestion step) the company is, the more power it will have when it comes to bundling. I anticipate that startups will try to expand their offerings left to right: those that own ingestion and transformation, will go into storage, and those that do storage, will try to get into analytics. Going from right to left (analytics to ingestion) is much harder because it goes against the data flow, and therefore requires much more effort to fight with the well-established competition.
Many predictions about the future of the industry tend to age quite badly. When it comes to data, a lot is obvious: locking in data in traditional SIEM solutions with no ability to use it for other purposes, and by other teams is not going to work long-term for every enterprise. There is no such thing as “security data” - there is business data that needs to be accessed and analyzed from different angles and by different teams; security is just one of many use cases. Even within security, many use cases such as data science, threat modeling, and data engineering cannot be accomplished when the data is locked in a SIEM. And, with the rise of AI and LLMs, security teams will likely be looking for new ways to leverage their data for purposes that cannot be supported by legacy tooling.
Although many mature security teams are excited about the potential of data lakes, they aren’t an answer for everyone either: many companies simply cannot fully take advantage of them, and the costs of building and maintaining a data lake aren’t zero (so are the costs of not architecting it well from day one).
I think as we go into the future, we will naturally see more adoption of the modern security stack, such as data lakes and security analytics, and the powerful use cases like detection engineering they enable. But, it won’t be as quick or as widespread as some in the industry may hope for. The security market is not homogenous, and organizations’ needs are defined by their unique business models, technology ecosystems, industries, geographies, use cases they need to support, cultures, and ways of working.

There will be different constellations of people and organizations that will embrace different approaches. Those that are focused on operational security use cases, analytics, and SOC, are likely to stick with SIEM or SIEM-like solutions however we choose to call them at the time. Those that have the business need, the talent, and the resources to explore advanced use cases such as detection engineering, security engineering, data engineering, and data science, will be adopting data lakes that come with a great promise to break down organizational silos at the data layer. Security is a field that requires a mixture of different analytical and data approaches. The question isn’t how to find a “one system to rule them all” on the industry level but how to reduce cost and complexity when sticking mixed architectures together.
The decoupling of the data acquisition, processing, routing, and analytics layers will continue to develop but it will likely be packaged differently depending on where in their journey a customer is: large enterprises will be leveraging federated data and an analytics layer over it, cloud-native companies will be storing their data in one place and having tools like Panther on top, some companies will adopt the SecOps Cloud Platform approach, and smaller players may integrate their SIEMs with different add-ons and plug-ins purpose-built for their analytics use cases. And, whether we like it or not, traditional SIEM is unlikely to disappear anytime soon.

Gratitude
This article would not have been possible without generous support from Matthias Vallentin & Oliver Rochford, willing to debate hard problems and share their decades of experience in the security data space. Additional thanks to Alex McGlothlin for reading the draft of the article.
35 pages? Ross, I print out and markup all your newsletters. And I'll do the same for this one - but 35 pages??? ; ) Great job. More content. More value. More food for thought. Thank you, Steven Palange.
Data is half of it.
The other half is a threat model that:
(i) survives changes in Entry Points,
(ii) is focused on critical events/behaviors (as opposed to every little technical hiccup), and,
(iii) related to (ii), is fast enough to stop stuff in minutes.