
AI might be killing traditional SIEMs, but data advantage is as strong as ever
A few thoughts about how AI agents are fundamentally changing SIEM and adjacent markets, and what this means for the future

Over 3 years ago, I talked about the concept of data gravity - the idea that as more and more data gets centralized in a single place, it gives a huge advantage to companies that collect this data. That idea made a lot of sense back then, in January 2023, some 2 months after the launch of ChatGPT. It makes very little sense today. AI agents have completely changed how we think about data, so much so that we have to talk about what this means for platforms formerly known as SIEM, SOAR, and everything in between.
Disclaimer: I know many founders in these markets. Many are friends, and in some companies I am an angel, so for my own sanity and to not offend anyone, I will only mention very established players that everyone in the industry knows. Please refer to market maps and such to answer “who is who” in the market.
This issue is brought to you by... Tines.
A new practical guide to AI adoption for IT and security teams
Successful AI adoption requires more than just turning on new features. It requires a mix of imagination, thoughtful tooling decisions, clear goals, and the right implementation.
Tines just released a new field guide that takes a more practical look at AI adoption for security and IT teams.
In this guide, you’ll find:
Inspiration on what workflow automation with AI could look like for you from Vimeo, Canva, Udemy, and JAMF
A step-by-step guide to find the right AI-powered intelligent workflow platform for your organization
Human-in-the-loop best practices to ensure smooth implementation
A quick refresher on the data gravity concept
To get started, here’s a quick refresher about data gravity (a copy-paste from that 2023 blog post).
“The idea [ of data gravity ] was first introduced in 2010 by Dave McCrory, a software engineer who observed that as more and more data is gathered in one place, it builds mass. That mass attracts services and applications, and the larger the amount of data, the greater its gravitational pull, meaning the more services and applications will be attracted to it, and the more quickly that will happen.
Data gravity leads to the tectonic shift in cybersecurity: security data is moving to Snowflake, BigQuery, Microsoft Azure Data Warehouse, Amazon Redshift, and the like. As the amount of data increases in size, moving it around to various applications becomes hard and costly. Snowflake, Google, Amazon, and Microsoft understand their advantage incredibly well and are taking action to fully leverage it. As it relates to cybersecurity, they typically do it in the following ways:
By offering their own security services and applications, and
By establishing marketplaces and selling security services and applications from other providers.”
Everything has changed since 2023, but just as much hasn’t
Reading this now with what we know about how things have evolved is kind of funny because of how much has changed, and how much hasn’t.
Let’s start with what has not changed.
First and foremost, the SIEM is still here, and Splunk continues to be the biggest player in this market. Cribl & other data pipeline tools were supposed to kill Splunk, but instead, I would argue they extended its dominance. It was obvious that companies would start using cheaper data storage options, and Cribl made it possible to say “Keep your Splunk, but send some data elsewhere”.
Second, the SIEM continues to dominate the security budgets at the enterprise. Despite all the add-ons and workarounds and stop-gaps and whatnot, SIEM has not exactly become cheaper, while the amounts of data it needs to process continue to explode.
Third, companies continue to centralize their data. There was a moment when it felt like it didn’t matter where the data lives, and we could just get away with different federated models, but that didn’t seem to have materialized.
On the surface, things look the same, but the moment you dig deeper, you quickly realize they are anything but.
The biggest shift without any doubt is caused by AI agents. I am not talking about how startups are reimagining what SIEM used to be (although that is surely a factor that, over time, will likely have a huge influence on the market). What I am talking about here is something much more fundamental: the fact that AI agents don’t care where the data lives.
AI agents challenge the very business model behind SIEMs
Historically, SIEM platforms would charge on ingestion, meaning the more data you send to them, the more money they make. Fast forward to 2026, and one thing has become clear: that AI agents don’t care where the data lives. In other words, if agents can query the data across tens of different sources and provide an answer in a single human-friendly interface, why would companies need to centralize all of their logs? That’s the big question that I am sure is causing some pretty bad insomnia for executives at large SIEM companies and data lakes.
I am not here to theorize that a year from now, agents are going to destroy SIEM or something dramatic like that, but the more you think about this, the more interesting it gets. I am also not talking about AI agents taking over, AGI inevitability, everyone getting replaced with AI, or some other pretty big moonshot topics. The question here is - are AI agents good enough to just go and query the data where it lives? And the answer to that is a resounding yes.
This brings me to the conclusion that AI agents challenge the very business model behind SIEMs because they weaken the data gravity effect SIEM vendors have been so fortunate to capitalize on.
Do I personally think that this is the end of data centralization? Not at all. The data has become so valuable that companies need to store it, and they want to centralize it. I don’t believe we will end up in a world with zero data centralization, but I also don’t think we’re going to go back to the time when all data lived in a single place anytime soon. What is happening instead is that more and more companies are creating a few separate islands for different kinds of data.
In practical terms, this means that fever and fever companies are going to be sending really high-volume, rare-value data like GKE logs or all VPC flow logs to Splunk, but that will no longer be a problem. If an agent can get to the bottom of that Wiz alert by going directly to GCP or AWS and getting the data they need in the moment, then the problem can be solved effectively without centralization. The more of these use cases we see, the more it will weaken the traditional SIEM.
While data gravity is getting weaker, workflow gravity is getting stronger
While data gravity is getting weaker, workflow gravity is getting stronger. I have recently explained that workflow gravity is when a system becomes the system of action where work happens, and then uses this position to pull other work into the platform. In my article from earlier this year, I explained that one of the things that makes the workflow gravity effect so powerful is the fact that it creates a flywheel.
“First, all work is centralized in one place, and all the incidents, changes, approvals, exceptions, tasks, evidence, etc., all of that becomes a record in a single workflow system. The more this system is used, the more context it accumulates. This context comes in all forms - change history, comments, links to additional information, and so on…
Once a single system accumulates so much business and technical context as well as history of what changed, when, how, and why, it becomes possible to automate triage, routing, prioritization, approvals, and remediation in a way that point tools struggle to do. The more automated it becomes, the more likely it is that anything still operating outside of these centralized systems will be integrated into the same workflow, as that’s where most of the work already occurs.” - Source: ServiceNow is betting on “workflow gravity” to win against the platforms of Palo Alto, CrowdStrike, Cisco, Zscaler, and Microsoft
While the above article I am referencing is primarily about ServiceNow, I think it’s very relevant here. What SIEM platforms are starting to realize is that just being a repository of data with some rules on top is no longer enough. Even though the data gravity effect is getting weaker, workflow gravity is getting stronger, and so smart SIEM players are realizing that if they can bring context and autonomous action into their data repository, they can win big. This realization is what drives what I can only describe as the enmeshment of data and workflows.
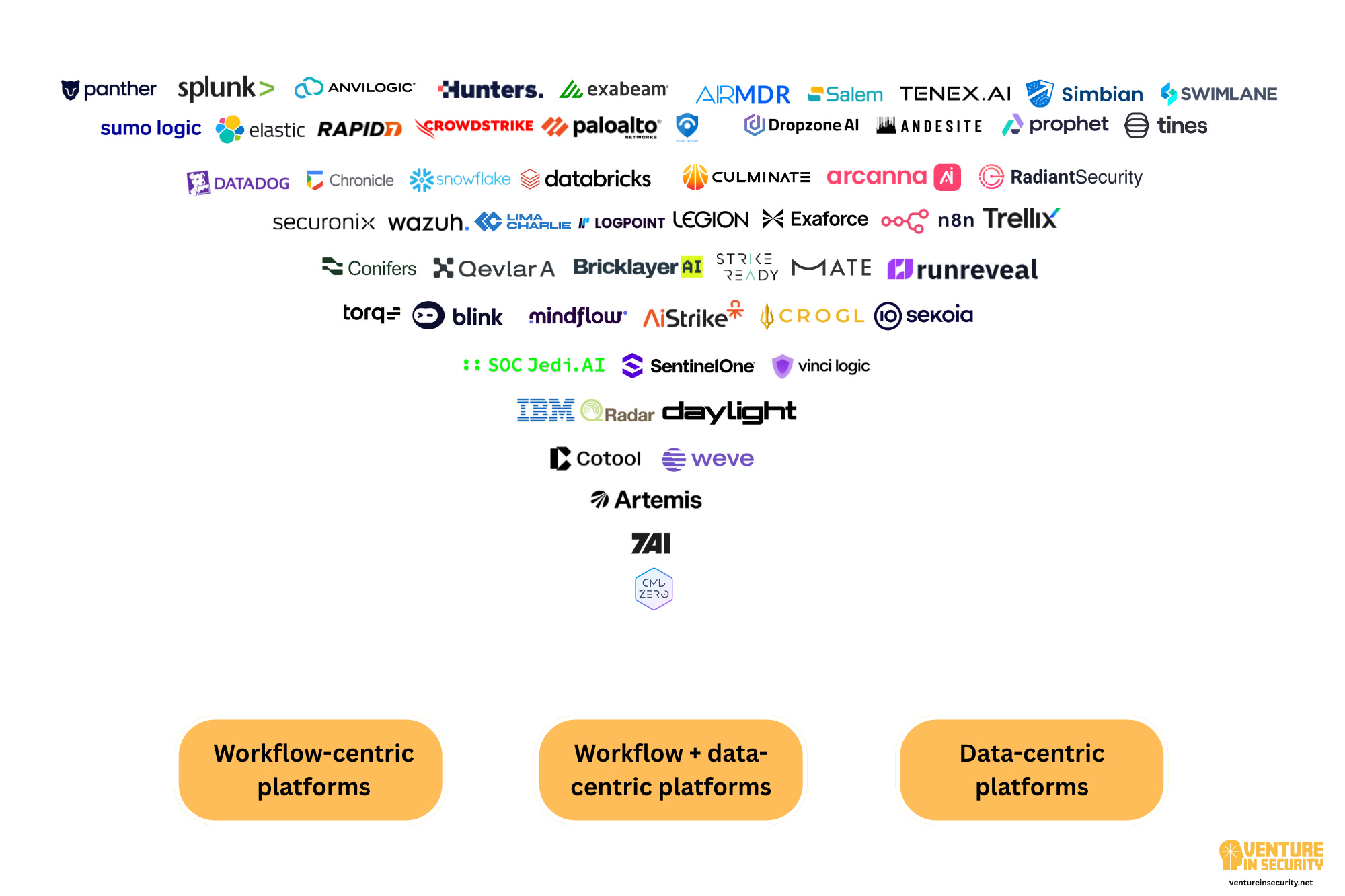
In the end, there will likely be 3 main types of players
When the market is a complete mess, everyone is doing their best to place bets they believe will help them win. While no one can predict the future, if things continue on the current path, I think we’ll end up with three main types of players: data-centric platforms, workflow-centric platforms, and platforms that combine both.
First, there will continue to be the need to centralize, store, and query data, so pure-play data platforms are not going anywhere. I don’t, however, think that we’ll see any new billion-dollar players focused on ingesting, normalizing, and storing security data alone. I am putting the emphasis on security here because I am sure we’ll see many generations of infrastructure companies built for the AI-first world, etc., but these aren’t SIEM platforms.
Second, there will continue to be companies deciding to double down on workflow-centric business and become really, really good at this. The workflow gravity effect I discussed before is, at least in theory, a great opportunity to innovate at this layer. I say “in theory” because in the pre-AI world, SIEM platforms were usually the ones acquiring SOAR players, not the other way around, so it’s interesting to think if that will change. Either way, there’s definitely a place for workflow-focused play, completely agnostic to where the data lives.
Last but definitely not least are the platforms that combine data and workflows. I don’t think one needs to be particularly smart to figure out that this is going to be the biggest and busiest category:
All the new AI SOC and AI MDR players are building the data + workflows layer from the ground up. I know many are taking different approaches, but fundamentally most (all?) of them are solving the same problem. The AI MDR players are building for their own human-in-the-loop, while AI SOC solutions are generally built for customers’ human-in-the-loop, but the approach is more or less the same with respect to data and workflows.
All the new AI-native SIEM players are trying to build intelligent SIEM, which in practical terms generally means bringing workflows into a data platform so that humans don’t have to spend time manually stitching and correlating things together.
Some of the platforms out there that were formerly focused on workflows (aka, SOAR) have also evolved into AI SOC by bringing in data into their workflow-native experiences.
Some of the platforms that were previously positioned as a SIEM are now starting to build workflows that extend to other data sources, essentially saying that “It would surely be great if you use our data layer, but even if you don’t, we will still bring a lot of value”.
Essentially, everyone is trying to eat everyone else’s lunch, and it’s going to be interesting to see how things will turn out.
Closing thoughts
Watching what’s going on in the SIEM and SOAR markets is fascinating. The previous generation of AI (ML) accelerated data gravity, while the new generation of AI (AI agents) seems to be destroying it. Some SIEM players are evolving their business outside of just data (after all, if data centralization & ingest go down, then something else needs to replace revenue, and many are seeing that the value is in becoming the system of action). Other players, on the other hand, are trying to enter the SIEM market.
It’s as if everything is changing, and nothing is changing at the same time. In the end, no company can do everything all at once, so we can reinvent all we want, but we’re probably still building a next-next-next generation of SIEM and SOAR. Hopefully, this time they will work better than before.
One thing I think is critical to call out is that while the data gravity may be weakening, the advantage of companies that have already accumulated a ton of data is not. On the contrary, with AI, the more data a company has, the better it can train its models and the more value it can bring to its customers. But that’s a completely different topic for another day.
Disclaimer: While Tines, a company that happens to be in the workflow automation space, is a sponsor of this piece, it has not in any way influenced its content, and I am pretty sure they would probably disagree with a lot of my thoughts. Just a reminder that Venture in Security sponsors do not have any influence on the content of the articles. In 99% of all the cases, I am able to avoid these coincidences, but inevitably they happen.
Directionally correct, I think that the advantage right now is for companies that can drive a unified approach between platform engineering servicing observability use cases and the SoCs utilizing a SIEM that mostly depends on this company-wide logging estate.
This has previously not been possible due to a deep separation between these teams, but "DevOps as a philosophy" did actually end up breaking barriers, aided by AI and CTOs overseeing both teams.