
What works against Mythos today is what worked against ransomware 5 years ago, and malware 10-15 years ago
In security or otherwise, trends are temporary. Stick to fundamentals.

Mythos completely changed the game, except, in most ways, it didn’t. It isn’t creating entirely new security problems, it simply makes existing problems much easier to exploit at scale. Yes, AI will increase breaches by making attacks faster and cheaper, but the way companies defend themselves hasn’t fundamentally changed. The organizations best prepared for AI-driven attacks are the same ones already prepared for ransomware and other modern threats.
If you are a regular reader of Venture in Security, you know that I am big on fundamentals. No matter what the topic is - security, building startups, investing, go-to-market, or anything else, fundamentals win. This is what today’s piece is about - focusing on fundamentals in the age of complete reinvention with AI.
This issue is brought to you by... Island.
Up to 10x Faster App Access. Full AI Visibility. What SASE Should Have Been.
Still routing traffic through distant proxies and watching AI tools, agents, and MCP calls disappear into blind spots? Legacy SASE is the problem.
Island’s SASE Perfect Packet architecture enforces policy at the browser and endpoint, before data moves. It’s in production across Fortune 500 enterprises with:
Up to 10x faster application access
90% of sessions direct with no backhaul
Deployment in as few as 5 minutes
And unlike proxy-based SASE, Island governs AI sessions, agent workflows, and tool calls at the point of intent with a full audit trail of what was sent, by whom, to which application.
No break-and-inspect. No VPN friction. No guessing.
Learn how Island delivers the complete SASE stack without the legacy proxy tax.
Over 90% of security problems are due to lack of operational discipline
If you read the Verizon DBIR or virtually any other credible breach report, you’ll see that while the cybersecurity market constantly evolves, with new tools, categories and buzzwords introduced every year, the actual reasons companies get breached remain almost unchanged. It’s rarely some novel, cutting-edge attack that takes a company down. It’s rarely something blockchain-powered, quantum-proof, AI-enabled, or whatever the new flavor of the day is. Instead, companies get breached because of the same familiar problems: misconfigurations, unpatched systems, third-party risk, identity mismanagement, flat networks, poor segmentation, and a handful of other operational oversights. The tech changes, the tools and architectures change, and attackers change their methods but in some ways the root causes of incidents for the most part stay the same.
The reality is, this is not a coincidence. Over 90% of security incidents, year after year, all go back to the same fundamental root cause: lack of operational discipline. Not a lack of budget (though that is increasingly becoming a problem), not lack of talent (although that too is a real issue), but an inability to consistently implement, monitor, and enforce the basics at scale.
I first heard the concept of “lack of operational discipline” from Yaron Levi, CISO at Dolby (I highly recommend Yaron’s amazing blog). Yaron has been championing this idea for years and it continues to surprise me that this isn’t a generally accepted concept and term.
The hardest security problems are not security problems
Over a year ago, Geoff Belknap, former CISO at LinkedIn, wrote a post that is probably the truest post ever written about security. Here’s what he said -
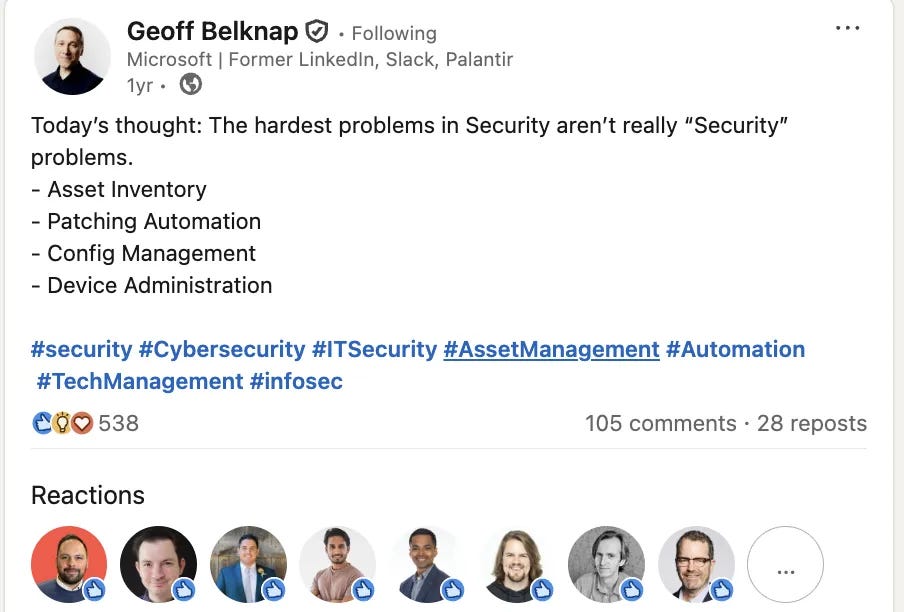
Image Source: Geoff Belknap on LinkedIn
Without any doubt, Geoff is right. If you think about this long enough, it’s clear that the vast majority of truly gnarly security problems indeed stem from what Yaron calls a lack of operational discipline by other teams across the organization such as IT, infrastructure and engineering.
Take asset inventory. Every security framework in existence starts with “know what you have,” but very few companies can actually produce a complete, real-time list of all their systems, cloud instances, or exposed assets. Nearly every organization (and I have to say “nearly” because many will never admit that they have this problem) have untracked servers running in forgotten AWS accounts, orphaned SaaS apps, or old test environments still connected to production data. The reality is that security teams can’t protect what they don’t know exists, but that doesn’t mean they’re not expected to still do it. Another example is patching automation. If we’re honest, we have to admit that vulnerability management programs exist largely because patching at scale is broken, across both engineering and IT. Reddit, for example, doesn’t have vuln management scanners and prioritization process; they’re known for just patching what needs to be patched. As an industry, we spend millions on scanners, dashboards, and prioritization algorithms to tell us what to fix simply because we can’t automatically fix it. If patching were fully automated across the stack, “vuln management” would be an operational metric, not an entire category of security tooling but there we are.
Configuration management is another textbook example. Misconfigurations remain one of the top causes of breaches year after year not because engineers don’t know what “least privilege” means, but because there are way too many systems to keep track of, way too many people involved, and way too few people who see the full picture of what’s going on. A single S3 bucket or Kubernetes namespace left open to the world can undo millions in security investment. Companies have tens of thousands of assets nobody can explain or even identify who owns them, let alone if they need to be there. Asset management is a complete mess but companies basically accepted that “that’s the way it’s always been” and moved on, only to get breached for some completely preventable reasons.
We can go on and on with different examples but the main point here is simple: if IT and engineering had the ability to consistently implement, monitor, and enforce the basics at scale, most of the security problems would simply go away.
Achieving operational excellence at scale is incredibly hard
Let me be very clear: the reason companies lack operational discipline is not because they are reckless or they don’t know why it’s important, but because it is incredibly hard.
Take user access management. In theory, the process sounds straightforward: give employees the access they need, review permissions regularly, remove unnecessary privileges, and ensure sensitive systems are tightly controlled. In practice, identity and access management is one of the biggest operational messes inside modern enterprises and one of the largest attack surfaces companies have.
Every new hire, role change, contractor onboarding, SaaS deployment, cloud migration, or vendor integration creates new permissions, groups, exceptions, and dependencies. Security and IT teams have to constantly evaluate who should have access to what, whether permissions violate least privilege principles, whether dormant accounts still exist, whether contractors were offboarded correctly, and whether changes could break critical workflows. Multiply this across hundreds of applications, multiple identity providers, cloud environments, legacy systems, and thousands of employees, and the complexity becomes overwhelming very quickly.
Over time, organizations accumulate years of temporary exceptions, stale accounts, overprivileged users, shadow IT integrations, and poorly understood dependencies. Eventually, nobody is fully confident about what can be safely removed without disrupting the business. As a result, companies often choose to tolerate excessive access rather than risk breaking operations.
And identity is just one example. You could replace it with cloud permissions, vulnerability management, endpoint security, or firewall policies and the story would look almost identical. That’s what lack of operational discipline really means in large enterprises: not negligence, but the sheer complexity of keeping systems clean, controlled, and continuously maintained at scale.
Lack of operational discipline becomes a security problem
The fact that companies struggle to maintain operational discipline at scale across a broad range of disciplines, from identity and access management, to asset inventory, patching, and so on creates problems for security teams. When companies don’t know what their applications are, which users should have what type of access to which applications, why a specific access path exists, how many Linux machines are there at the company and who owns them, who all the third parties that have access to the company environment are and how that access is being used, - when companies can’t answer these and many other fundamental questions, security is left trying to fix problems it didn’t create.
When security teams are forced to deal with the lack of operational discipline, their only real option is to gain visibility into the mess and hope that, by exposing how bad things are, they can push IT, infrastructure, or engineering to fix the root causes or at least the symptoms. That’s exactly why posture management tools exist. CSPM, DSPM, SSPM, and the rest were all designed to help security teams see and manage risk created elsewhere in the organization. These tools don’t solve the underlying problems, they simply make them more visible. A CSPM can flag an exposed S3 bucket or an over-privileged role, but it can’t prevent them from being created. Posture management, in the end, is security’s way of coping with the operational gaps it doesn’t control.
Solving these problems requires developing operational discipline
If lack of operational discipline is creating security problems, then the solution can’t just be another detection tool or a fancier dashboard. Companies have little choice but to deliberately build operational discipline into how they work. In practice, this has to start with accepting that security cannot “fix risks” on its own. Operational discipline lives with IT, infrastructure, and engineering, so security can guide, influence, and enable, but the work itself has to be embedded into day-to-day operations of other teams. That means moving from one-off cleanups and reactive firefighting to boring, repeatable, and stable processes that run continuously.
To make this happen, organizations have to invest in tools that don’t just show misconfigurations after the fact, but help teams understand why something exists, who owns it, and what will break if it changes. Whether it’s identity governance, asset inventory, patching, or any other area, the goal across the board is to reduce ambiguity, and help companies do the basics at scale well.
Tools, however, aren’t the most important part, nor should they be seen as the starting point to improve operational discipline. The main shift is about processes and culture. One of the most effective patterns I’ve seen is treating operational hygiene as a first-class engineering responsibility, not a security tax. A simple but powerful example is dependency management. I’ve seen companies where the CTO made it clear from day one that engineers were expected to update dependencies every week. There were no heroic patching sprints, no six-month backlog of vulnerable libraries, just a steady, disciplined cadence. That single expectation dramatically reduced risk, but more importantly, it normalized the idea that “keeping things clean” is part of the job, not something you do only when security asks. Cultural transformations like this require buy-in from leadership. Teams need air cover to do this work, because operational discipline often competes with feature delivery and short-term business goals. When leaders explicitly value reliability, clarity, and maintainability, and reward teams for reducing complexity instead of adding to it, behavior changes and people start caring about things more.
The bad news is that doing the basics well at scale isn’t easy today, and it won’t magically get easy tomorrow. There are tools that help, AI helps a lot, but no solution will remove the need to do the work. The good news is that I am seeing more and more organizations realize that their biggest security risks are not sophisticated attackers, zero-days, or nation-states, but fragile systems held together by scattered knowledge and people trying to do their best. They understand that security, at its core, is an operational outcome, and while achieving operational excellence at scale is incredibly hard, it’s also one of the highest-leverage investments an organization can make. As complexity continues to grow, the companies that invest in operational discipline will move faster, break less often, and get breached less frequently.
’ll end this piece exactly where I started it - that what works today against Mythos is what worked 5 years ago against ransomware, and what worked 15 years ago against malware, and what will work 10 years from now against whatever new problems we’ll be dealing with.
In security or otherwise, trends are temporary. Stick to fundamentals.

100%
The speed and ability to be nimble is more important now more than ever, but the fundamentals stay the same.
Fundamentals don’t just win—they fail silently when authorization is missing.
What this highlights for CISOs is the real gap isn’t visibility or detection, it’s enforcement. EnforceAuth addresses this by embedding real-time authorization directly into workflows, so misconfigurations, over-privileged access, and AI-driven actions are stopped at decision time—not discovered after the fact.
Most “operational discipline” failures are really authorization failures at scale. And as AI accelerates everything, polite AI ≠ secure AI—without deterministic policy enforcement, you’re just automating risk faster.