
PAM is not dead, it’s evolving
PAM following Palo Alto's acquisition of CyberArk

This week, I am publishing a contributed article from a friend, Shashwat Sehgal, an identity and cloud security expert best known for his security startup, P0 Security. In this piece, Shashwat is synthesing his lived experience from talking to 500+ companies using and buying PAM over the last few years. I asked Shashwat to share his thoughts about PAM following Palo Alto's acquisition of CyberArk.
Unless you are living under a rock, if you work in cybersecurity, you are aware of Palo Alto Networks’ acquisition of CyberArk, announced in late July 2025. This announcement predictably sparked a flurry of debate, with many leading voices voicing pessimism about the deal, saying “PAM is dead. Why is Palo Alto wasting $25B on a dying architecture?"
In this article, I’ll argue that the reality is the exact opposite. In an age of cloud-native developments and agentic applications, PAM has never been more relevant. And PANW’s move is the logical next step of the “platformization” strategy that Nikesh Arora set in motion a few years ago. Let’s start by analyzing PANW’s strategy, and why this move made so much sense for them.
Palo Alto Networks, and their strategy of platformization
As Ross and I argued in a previous piece on platform evolution, no cybersecurity company starts off as a platform. Instead, they earn the title by evolving and growing alongside their environment. Both CyberArk and PANW are prime examples in their own right.
CyberArk created the PAM category in the early 2000s. Its first product was their enterprise vault, and by the 2020s, it emerged as the clear leader in PAM, with ~40% of the market share. Lately, it began expanding to become a platform for “workforce identity” security, with its moves in IGA (acquisition of Zilla Security in 2025), as well as IAM (acquisition of Idaptive in 2020).
Palo Alto Networks, meanwhile, has been executing on a “mega-platform” strategy, aiming to span all the big rocks of cybersecurity. Identity was their one missing piece. Nikesh has been vocal in the past that PANW was not an identity company. But he likely meant that they were not an “IAM”, or “Identity Management” company, since IAM tools are usually (though not always) sold to IAM teams that report to CIOs. PANW’s GTM targets CISO, and so, an IAM play was never a good fit for their strategy.
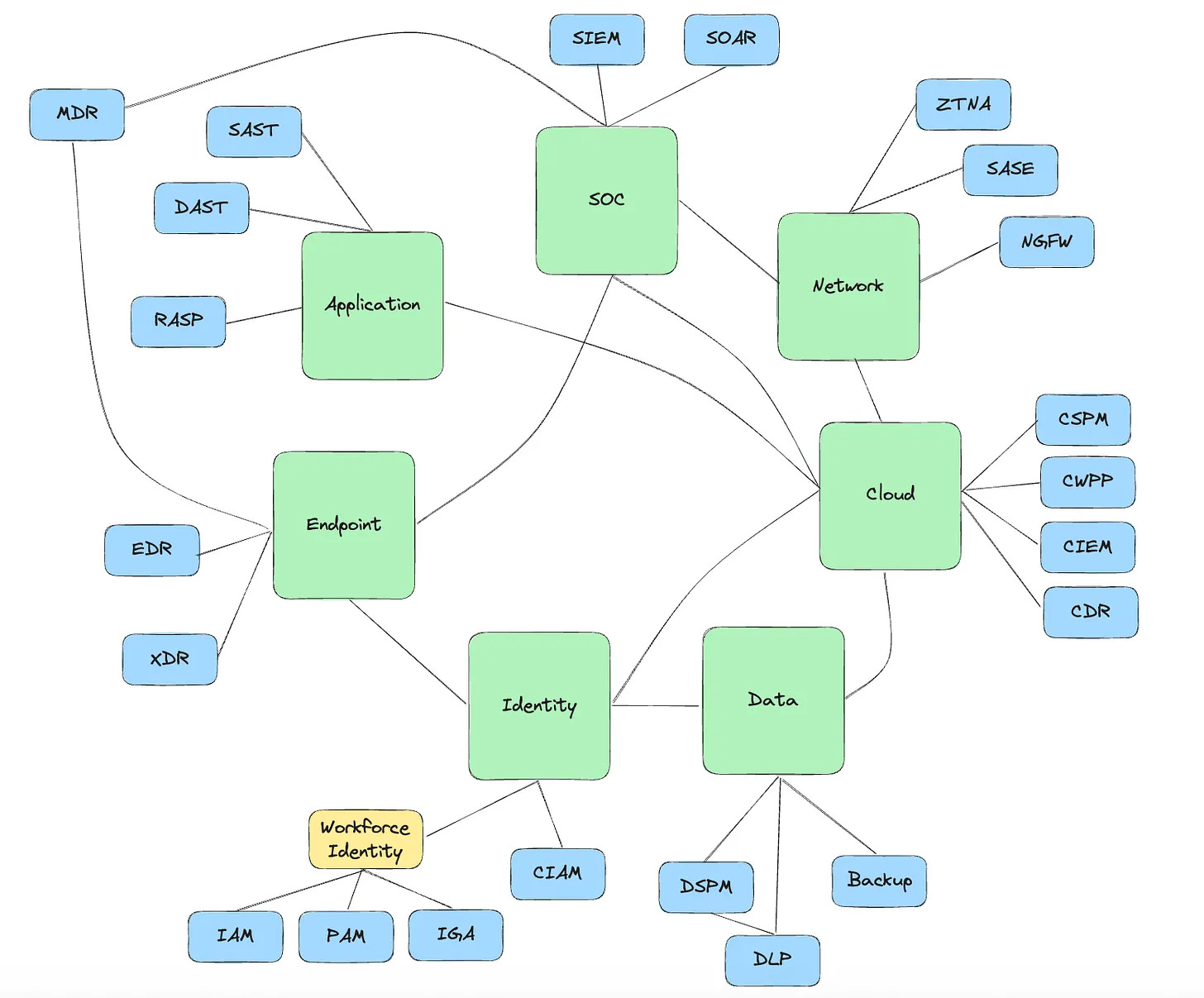
However, PAM and IGA do fall under the CISO’s budget, so, to fill their gap in identity, it was always more likely that PANW would acquire either an IGA or a PAM company. But why a large, established company? In the recent past, PANW has acquired modern best-of-breed startups (e.g. Talon, Dig Security, Protect.ai etc.) in the $200M-$600M range, so wasn’t a $25B acquisition out of character?
The idea behind each of PANW’s smaller acquisitions has been simple - buy the best-of-breed product, and attach it to the GTM of an existing PANW product line. E.g., Talon was attached to the PANW’s SASE, with the simple strategy of extending a customer’s SASE fabric all the way to the endpoint (browser). Success follows naturally, as those products can be bundled with an existing motion. Identity is not so simple. Since they did not have any presence so far, a smaller identity startup acquisition would likely not have been successful. After all, what existing selling motion could a startup’s product attach to? So in order to be successful at identity, PANW needed a beachhead and a brand, more than a technology. And hence, a large acquisition was inevitable.
This reduced the universe of acquisitions to a handful of large IGA and PAM companies. And given their inclination of going after the best-of-breed, it further narrowed the shortlist to Sailpoint (IGA) and CyberArk (PAM). My suspicion is that CyberArk likely won because of a wider portfolio than Sailpoint, given their presence in PAM, and IGA to a lesser extent.
This explains why they made a move for CyberArk, but it does not explain the premium that they paid. A common refrain was “PAM is a legacy tech with no growth. Why overpay (25x revenue) for a beachhead?” To understand why, we need to know the history of PAM, how it adapted to each wave of infrastructure change, why it’s evolving again now, and why will it be an area of massive growth for years to come, thus likely justifying the premium.
But first, what exactly is PAM?
At its core, Privileged Access Management solutions help organizations control their workforce’s access to their most sensitive assets. These are usually their production stacks, which host their most business-critical applications and workloads, where a single breach could bring their business to a stop. They include servers, core databases, Kubernetes clusters, public cloud consoles, and code repositories. PAM ensures that only the right identities, whether human, machine, or agentic, can reach those systems, with only the permissions they need, for only as long as necessary, and with full audit trails.
Its core goals have remained constant for more than two decades: every privileged access should be short-lived, least privileged, and auditable. What has changed is the nature of the systems, the types of identities involved, and the mechanics of granting and enforcing access. Let’s explore these mechanics. To achieve these goals, across all phases of its history, every PAM solution, explicitly or implicitly, has had to solve three core workflows:
User Provisioning - Create a user account in the target system.
Authentication (authn) - Verify who is requesting access.
Authorization (authz) - Define what they’re allowed to do once authenticated.
As technology has evolved, the way PAM solutions have solved these core workflows has also changed.
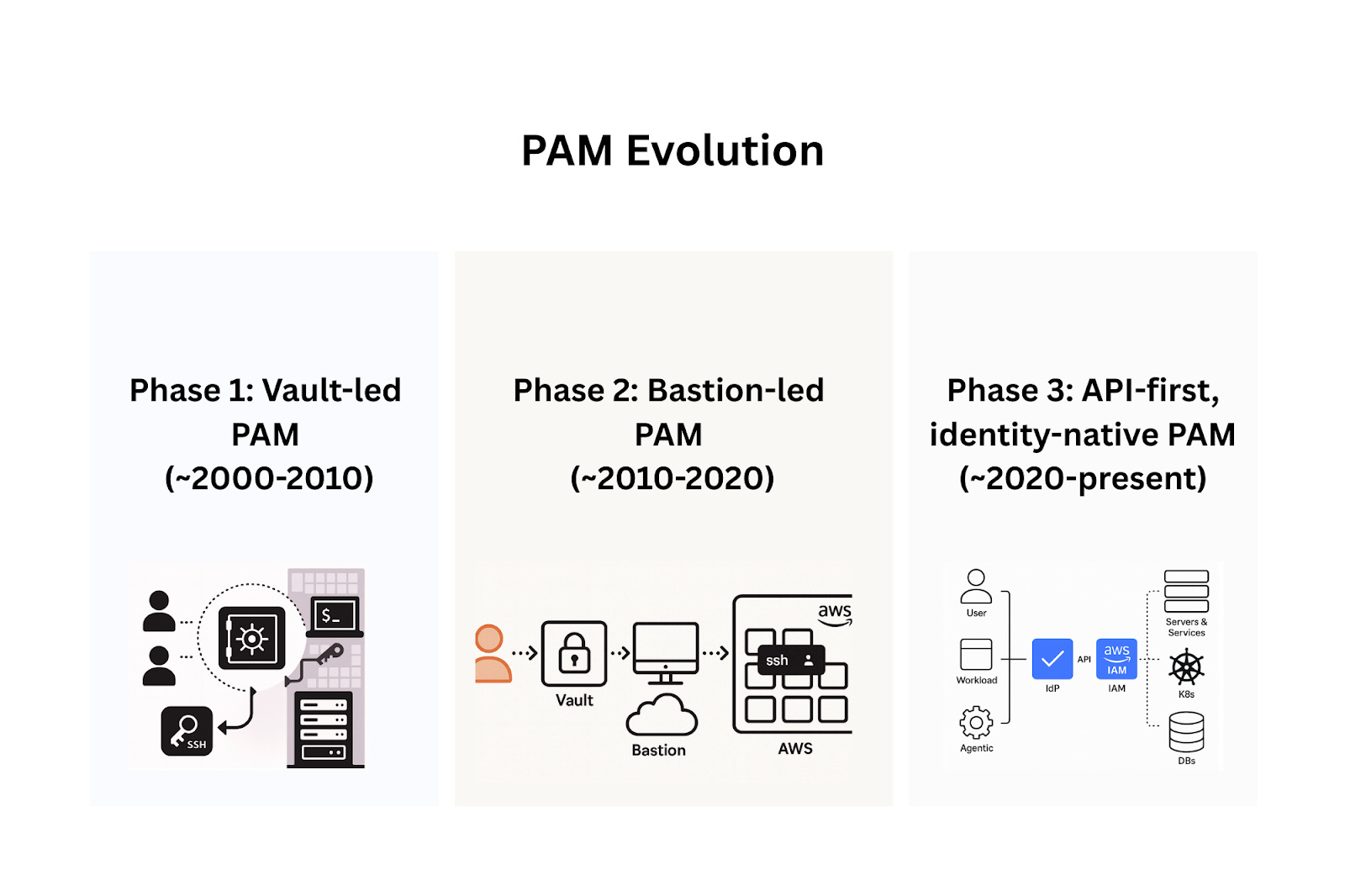
Phase 1: Vault-led PAM (~2000-2010)
In the early 2000s, enterprise workloads lived in corporate data centers. Privileged assets usually meant physical servers and databases in these data centers. Privileged access was simple to define: it meant the ability to perform “dangerous” tasks on this infrastructure, such as rebooting a production server, changing a database schema, or migrating a production database. Typically, this meant access to root, db_admin or sysadmin accounts, which were commonly required by sysadmins, DBAs, or senior network engineers. Access was granted to these privileged accounts using passwords. The challenge was that these passwords were typically shared amongst various users. Moreover, they were frequently stored in insecure ways: Excel sheets on shared drives, plain-text files, or even on post-it notes.
The risks were obvious. In 2002, Sarbanes Oxley mandated that companies needed to control and audit access to sensitive systems. Shared credentials made it next to impossible to assign accountability and trace who had access, or who made changes. The obvious answer was the enterprise equivalent of a password manager, or a vault. These first-generation PAM systems stored privileged credentials in an encrypted vault. They required authentication (via AD, often with MFA) to retrieve a password, logged all actions, and in many cases, rotated the password after use to ensure it could not be reused.
CyberArk was the most successful vault-led PAM. Other vendors included BeyondTrust and Thycotic (which later merged with Centrify to form Delinea).
Vault-led PAM usually supported privileged actions such as SSH/RDP sessions, or database operations. Over time, vaults added session recording (keystrokes and screen video), granular policies (restricting which accounts could be accessed when, by whom, and for what purpose), and alerting for unusual usage patterns (e.g., root access outside maintenance windows).
Why was this the right architecture? To answer this, let’s look at how vault-led PAMs solved the three core workflows in our framework:
User Provisioning was straightforward. Static privileged accounts already existed on the target machines, and nothing more needed to be done.
Authentication was performed through vaulted credentials. They were rotated automatically to make them short-lived.
Authorization was also straightforward. Each key mapped to a specific privileged account with fixed privileges, and this achieved least-privilege statically.
Because the number of systems was small and relatively static, provisioning and authorization were trivial. Authentication was the bottleneck, and vaulting (with rotation) was the right solution for the time. Vault-led PAM was very successful in the pre-cloud era, but as virtualization and cloud adoption accelerated, and privileged assets began to explode, this model began to break.
Phase 2: Bastion-led PAM (~2010-2020)
By the early 2010s, the public clouds (AWS, Azure and GCP) had started going mainstream, into production environments. Additionally, VMware and Hyper-V made it trivial to spin up and spin-down servers on demand. For a while, organizations tried to force-fit vault-led PAM for these new environments. The cloud was different - the number of servers and databases was a lot higher than in static, physical data centers. As a result, the number of SSH keys, db credentials and root passwords that required management multiplied.
The vault model couldn’t handle this explosion of credentials, creating an operational and security nightmare. Because it wasn’t built for developer workflows, developers and DevOps teams spun up new secrets and keys freely, with little governance. This led to a secret sprawl across the stack, e.g. SSH keys in Ansible playbooks, passwords in Terraform variables, and DB credentials in Jenkins pipelines.
The solution to this problem was a bastion-led PAM. DevOps teams started using hardened gateways (called jump hosts, bastions or proxies) on the edge of the network, as the single point of entry for privileged sessions. Instead of checking out a credential for each target system, engineers authenticated once to the bastion, which then proxied them into the target system. The vault only needed to store the bastion’s own credentials. Operationally, this was a big improvement. An engineer would SSH into the bastion (often using a key stored in the vault), then run commands to reach the target system. The bastion would inject the target’s credential on behalf of the user, and log or record the session for audit purposes. Everything flowed through a single choke point that the security team could monitor.
In workflow terms:
User Provisioning - Accounts created on the bastion, often mapped to IdP identities; target systems still relied on shared service accounts.
Authentication - Vaulted SSH keys for the bastion; static keys or passwords for shared accounts on targets.
Authorization - Often broad and standing; once on the bastion, access to targets persisted without time limits.
Integration with IdPs improved during this period. Some vendors began calling their products “identity-aware proxies” because they could correlate a bastion login with an individual in the IdP, but these systems weren’t truly identity-native: the underlying targets still used shared or temporary accounts. The bastion itself became another control plane requiring governance, with its own accounts, role assignments, and review cycles. Notable vendors included ScaleFT (acquired by Okta), StrongDM, and Teleport.
By the late 2010s, another shift was under way. Applications were increasingly cloud-native, and the most privileged operations were no longer about reaching a machine or a database over the network. Instead, privileged access was about securing API calls, such as changing IAM roles, destroying databases, altering storage policies, and deleting Kubernetes containers, that a bastion could not feasibly proxy. The bottleneck shifted to authorization: granting just enough privilege for just long enough, in a world where “privileged actions” now lived at the API level, not the network.
Phase 3: API-first, Identity-native PAM (~2020-present)
By 2020, there were a couple of important changes underway in the tech stack. Firstly, as discussed, the IAM APIs of all major cloud providers had become robust enough that most privileged operations could be performed through them rather than over network connections. Secondly, privileged actions themselves, such as connecting to a production cluster or database, were no longer limited to human users. Non-human identities, including workloads and CI/CD pipelines, using constructs such as AWS IAM roles, Azure AD service principals, or GCP service accounts, could delete databases, grant administrator rights, or alter storage policies. These non-human identities often outnumbered human users many times over and required the same level of governance in a modern PAM program.
Authentication had matured. For humans, SSO (Okta, Azure AD) + MFA logins became a standard. Workloads and machines used short-lived credentials: AWS STS session tokens, Azure Managed Identities, GCP Workload Identity Federation. Static secrets were being replaced with passwordless, ephemeral authentication, natively provided by the cloud providers. The hard problem was authorization. Privileged access meant controlling entitlements: who can do what, where, and for how long. Standing privileges such as long-lived admin permissions in IAM roles, cluster-admin roles in Kubernetes and overly permissive GitHub access tokens, became the biggest attack surface. Breaches repeatedly showed attackers exploiting these to gain access to a privileged environment.
Identity-native PAM delegates user provisioning and authentication entirely to the IdP/SSO. Privilege is provisioned via native CSP APIs:
An engineer requests a privileged role for a specific task, such as sudo into a VM
PAM checks policy and context, optionally requiring human approval.
PAM calls the platform API to grant the role, scoped and time-bound.
When time expires, PAM revokes the privilege automatically.
In workflow terms:
User Provisioning - Accounts are tied to identity in the IdP; There are no pre-created local or shared accounts.
Authentication - SSO for humans; short-lived tokens or managed identities for machines; passwordless methods where possible.
Authorization - Fine-grained and ephemeral; defined in the native IAM language; provisioned and revoked as needed with automation.
It is important to note that Identity-native PAM is fully backward-compatible with the previous generations of PAM. The use cases of a bastion-led PAM are fully covered by Identity-native PAM, but the vice-versa is not true. As an example, if an engineer needs to ssh into an EC2 (a typical use case of a bastion), Identity-native PAM can achieve that by provisioning roles in the cloud-provider’s native IaP (e.g. AWS SSM, GCP IaP, Azure Bastions). However, if an engineer needs read access to an S3 bucket (typical use case of an Identity-native PAM), a bastion can not easily support that.
To summarize, modern Identity-native PAM is an orchestration layer that:
Delegates authentication to IdPs.
Grants and revokes privileges via native IAM APIs.
Governs with approvals where necessary.
Ensures every action is logged and attributable.
Covers any identity that can perform a privilege operation via an API - human, workloads and agentic.
However, orchestration alone isn’t enough. In hybrid, multi-cloud environments, privileged access spans dozens of control planes: including AWS IAM, Azure RBAC, GCP IAM, Kubernetes RBAC and GitHub RBAC; many are outside any single tool’s direct control. For an organization to successfully operationalize a PAM platform, an organization needs to know where privileged access exists in the first place (after all, you can only manage what you see and know).
Identity-native PAMs achieve this using a visibility layer that shows every identity, every entitlement, every credential, and every path to privilege. This enables:
Visibility into standing admin permissions or static credentials.
Highlight risks such as lateral movement risks or overprivileged accounts
Most importantly, identify privileged access that must be eventually managed via PAM
What’s next for PAM, PANW & CyberArk
As we have seen, PAM is hardly dead. When well-intentioned folks say “PAM is outdated”, what they really mean is that vault-led PAM is outdated. In today’s age, with the network perimeter evaporating, it's a cliché to say that identity is the new perimeter, and “Identity-native PAM” is here to stay.
This, however, does not answer the question, how big (and fast growing) is this market? Why did PANW feel the need to pay a premium? As PANW alluded to in their remarks after the acquisition, the growth will come from agentic identities. The same principles that have guided PAM for over two decades (short-lived access, least privilege, and auditability), now apply to AI agents. They fit naturally into an Identity-native PAM model because they also perform privileged operations via the target system’s APIs, for example, creating a pull request in a sensitive GitHub repository. These operations require ephemeral credentials, tightly scoped permissions, and complete logging. For example, a developer-assistant LLM integrated into a CI/CD pipeline might request a short-lived deployer role in AWS to push a build. Modern PAM would verify the request, grant the role for the duration of the build, and revoke it automatically, with the entire event logged in its audit trail.
Coming back to the PANW/CyberArk debate, CyberArk’s core product, responsible for the bulk of their revenues, is their vault-led PAM. While they have invested in upgrading its capabilities for the modern stack, it's a safe assumption, like it is elsewhere in enterprise software, that PANW will need to keep upgrading the core asset to keep up with new technologies. And it will be much easier to return to their tried and tested strategy, of acquiring $200-$600M startups, and attaching them to their (new) beachhead.
PAM is not dead, it’s evolving. The leaders in this next chapter, at PANW and elsewhere, will treat identity as the control plane, integrate deeply with native IAM APIs, and apply least-privilege principles to every identity - human, workload or agentic.
If you like my blog, please subscribe & share it with your friends. I do this in my free time, so seeing the readership grow helps me to stay motivated and write more. I don’t send anything except my writing and don’t sell your data to anyone as I have better stuff to do.
If you are a builder - current or aspiring startup founder, security practitioner, marketing or sales leader, product manager, investor, software developer, industry analyst, or someone else who is building the future of cybersecurity, check out my best selling book, Cyber for Builders.
If your company is interested in sponsoring Venture in Security, check out Sponsorships.
Lastly, check out the Inside the Network podcast where we bring you the best founders, operators, and investors building the future of cybersecurity.
 | A guest post by
|
Great analysis on the PANW-CyberArk deal. Given the TAM expansion fueled by the surge in NHIs, does PAM alone still cover it? Really appreciate the article, I've gained a lot from it!